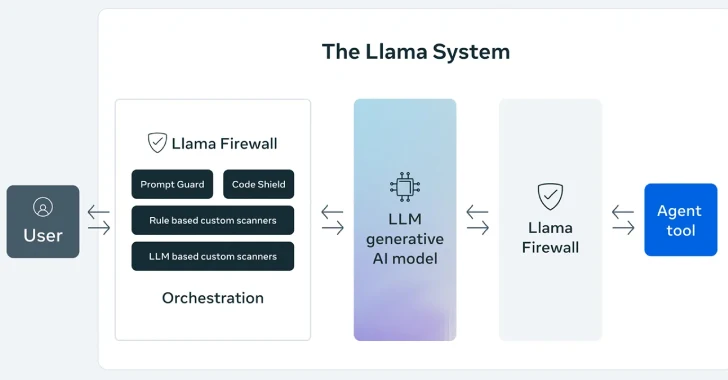

Metaは火曜日に、発表しました。LlamaFirewallは、プロンプトインジェクション、脱獄、安全でないコードなどの新たなサイバーリスクから人工知能(AI)システムを保護するために設計されたオープンソースのフレームワークです。
このフレームワークには、PromptGuard 2、エージェント整合性チェック、CodeShieldを含む3つのガードレールが組み込まれていると、同社は述べています。
PromptGuard 2は、リアルタイムでの直接的な脱獄やプロンプトインジェクションの試みを検出するよう設計されており、エージェント整合性チェックは、目標の乗っ取りや間接的なプロンプトインジェクションのシナリオを検査することができます。
CodeShieldは、AIエージェントによる安全でないまたは危険なコードの生成を防ぐことを目的としたオンライン静的解析エンジンを指します。
“LlamaFirewallは、LLMを活用したアプリケーションを保護するための柔軟なリアルタイムガードレールフレームワークとして構築されています”と、同社はGitHubのプロジェクト説明で述べています。
“そのアーキテクチャはモジュラーであり、セキュリティチームや開発者が、生の入力取り込みから最終出力アクションに至るまで、単純なチャットモデルから複雑な自律エージェントにわたる層状の防御を構成できるようにします。”
LlamaFirewallに加えて、MetaはLlamaGuardとCyberSecEvalの更新バージョンを提供し、さまざまな一般的な違反コンテンツをより良く検出し、AIシステムの防御サイバーセキュリティ能力を測定できるようにしました。

CyberSecEval 4には、AIによるパッチ適用として知られるアプローチを通じて特定されたC/C++の脆弱性を自動的に修正する大規模言語モデル(LLM)エージェントの能力を評価するために設計された新しいベンチマーク、AutoPatchBenchも含まれています。
“AutoPatchBenchは、AI支援の脆弱性修正ツールの効果を評価するための標準化された評価フレームワークを提供します”と、同社は述べました。”このベンチマークは、ファジングで発見されたバグを修正するためのさまざまなAI駆動アプローチの能力と限界を包括的に理解することを目的としています。”
最後に、Metaは、詐欺、詐欺行為、フィッシング攻撃で使用されるAI生成コンテンツを検出するなど、特定のセキュリティ課題に対処するために、パートナー組織やAI開発者がオープン、早期アクセス、クローズドAIソリューションにアクセスできるようにする新しいプログラムLlama for Defendersを開始しました。
これらの発表は、WhatsAppがプレビューした新技術、Private Processingが、ユーザーがプライバシーを損なうことなくAI機能を活用できるようにするために、リクエストを安全で機密性のある環境にオフロードすることを可能にする中で行われました。
“私たちは、セキュリティコミュニティと協力してアーキテクチャを監査し改善を続け、製品に導入する前に研究者と協力してオープンにPrivate Processingを構築し強化していきます”と、Metaは述べました。