ハルシネーション(幻覚)は、LLM(大規模言語モデル)にとって継続的かつ不可避な問題です。なぜなら、それは設計上のバグではなく、動作の副産物だからです。しかし、もしそれがいつ、なぜ発生するのかを知ることができたらどうでしょうか?
「ハルシネーション――もっともらしいが誤った、捏造された、あるいは意味不明な内容の生成――は、単に一般的なものではなく、すべての計算可能なLLMにおいて数学的に避けられないものです…ハルシネーションはバグではなく、LLMの構造上必然的に生じる副産物であり、エンタープライズ用途にとっては致命的です」とSrini Pagidyala(Aigo AI共同創設者)はLinkedInで述べています。
Neil Johnson(ジョージ・ワシントン大学物理学教授)はさらに踏み込み、「もっと懸念すべきは、ユーザーが気づかないうちに、出力が途中で良い(正しい)ものから悪い(誤解を招く、または間違った)ものへと突然変化することです」と語ります。
AIの利用は信頼とリスクのバランスです。そのサイバーセキュリティへの利点は無視できませんが、常に誤った応答が返る可能性があります。Johnsonは数学の力を借りて、予測不可能なハルシネーションに予測可能性を加えようとしています。彼の最新論文(Multispin Physics of AI Tipping Points and Hallucinations)は、以前の論文で述べた議論を拡張しています。
「多スピン熱系への数学的マッピングを確立することで、AIの『原子』(基本的なAttentionヘッド)のスケールで隠れた転換点の不安定性を明らかにしました」と彼は書いています。この転換点こそが、数学的な必然性が実際の現実となる瞬間です。彼の研究はハルシネーションを根絶するものではありませんが、可視性を高め、将来的にハルシネーションの発生率を減らす可能性があります。
AIの利用が増加し、AIの出力が人間の専門家よりも信じられやすくなっている現状を踏まえると、「見逃された良い出力から悪い出力への転換による被害や訴訟は、医療、メンタルヘルス、金融、商業、政府、軍事など、あらゆるAI分野で世界的に急増することが予想されます」。
彼の解決策は「出力の転換点を明らかにし、説明し、予測するシンプルな公式を導き出すこと、そしてユーザーのプロンプト選択や学習バイアスの影響も示すこと」です。
基礎となるのは理論物理学の概念である多スピン熱系です。『スピン』とは粒子の量子的な性質や状態を指します。多スピン系は、これらの粒子の集まりがどのように相互作用するかをモデル化します。熱系はプロセスに「熱」を加え、個々の「スピン」が二進的に状態を反転させることを引き起こします。
広告。スクロールして続きを読む。
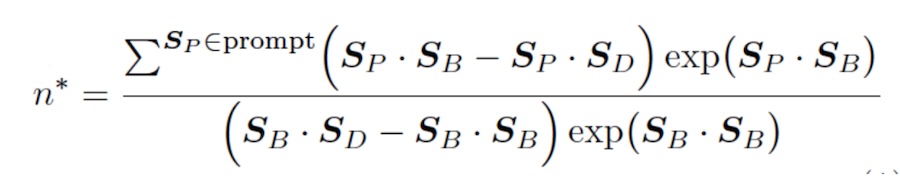
Johnsonは、生成AIのAttentionエンジンと多スピン熱系との間に数学的な等価性を確立しました。スピンはAIのトークンに相当し、熱的要素はAttentionエンジンに組み込まれたランダム性の度合いに相当し、関与する相互作用はトークン同士がどのように影響し合うかに対応します。
このモデルによりJohnsonは、トークン/スピンが不安定になりハルシネーションを引き起こす転換点を予測できる公式を開発することができました。
「シンプル」という言葉は相対的ですが、この公式は、初期プロンプトP1、P2などが与えられた場合、B(良いトークン=正しい)出力がこの数だけ続いた直後に、D(悪いトークン=ハルシネーション)型出力への転換点が訪れることを示しています。
Johnsonが正しければ、この知識はハルシネーションを止めるものではありませんが、転換点を把握することでAI設計者が発生率を減らす助けとなり、理論的にはユーザーがそれが発生したタイミングを知る手助けにもなります。「これは、応答が完了してから評価する必要があるほとんどのハルシネーション検出/修正アプローチとは異なります」とBrad Micklea(Jozu CEO兼共同創設者)はコメントしています。「例えば、不確実性定量化は実証済み(成功率約80%)ですが、応答が生成されるまで実行できません」。
しかし、Johnsonの公式が正しければ、LLMは自らの応答をリアルタイムで監視し、悪い応答が発生している最中にそれを停止できるようになるかもしれません。実装は難しく、計算能力の増強や応答時間の短縮が求められるため、基盤モデルのビジネスプランには合わない可能性もあります。
Diana Kelley(Noma Security CISO)は、OpenAI自身の研究で、性能向上がハルシネーションの増加を伴うことが示されていると指摘します:GPT o3はベンチマークテストの3分の1で、GPT o4はほぼ半数でハルシネーションを起こしました。今後のモデルで性能を下げ、コストを上げることは基盤モデルにとって難しい選択肢です。
「しかし、自己ホスト型モデルでは、医療や防衛などハルシネーションのリスクが追加コストを正当化する用途において、より価値があるかもしれません」とMickleaは付け加えます。
Johnsonは、自身の研究が示唆する2つの新しい設計戦略が将来モデルの性能を向上させる可能性があると考えています。1つ目は「ギャップ冷却」と呼び、「2つの主要な相互作用ペアの差が近づきすぎたとき(つまり転換点直前)に、その差を広げる」ことです。
2つ目は「温度アニーリング」と呼び、「出力の転換リスクと過度な出力ランダム性のバランスを取るために温度ダイヤルT′を制御する」ことです。
「もしAIモデルが信頼できない応答をし始めるタイミング――つまり『転換点』に近づいたり、ハルシネーションが発生しやすくなったりするタイミング――を予測できれば、デジタル会話の安全性と正確性を保つ上で大きな変革となるでしょう。こうした瞬間をリアルタイムで検知できる自動ツールがあれば、ユーザーは自分が見たり読んだりするものをより信頼できるようになり、怪しい応答が害を及ぼす前に検出する追加のレイヤーがあると安心できます」とJ Stephen Kowski(SlashNext フィールドCISO)は述べています。「リスクのあるAIの挙動をフラグする技術があれば、人々はオンラインでより賢明な選択ができ、脅威が本格的な問題になる前に阻止できます。AIがさらに賢くなるにつれ、これが誰もが期待すべき保護のあり方です」。
しかし、Johnsonの研究はまだ理論段階です。有望に見えますが、直ちにハルシネーションが劇的に排除されたり、減少したりすることは期待すべきではありません。「結論として」とJohn Allen(Darktrace SVP兼フィールドCISO)はコメントしています。「理論的には興味深いですが、組織はすぐに実用化されるとは期待すべきではありません――ただし、将来のモデル開発アプローチに役立つ可能性はあります」。