人工知能は、GitHub Copilotのコード補完から内部ナレッジベースを即座に検索するチャットボットまで、企業の生産性に大きな変化をもたらしています。新しいエージェントはそれぞれ他のサービスに認証する必要があり、企業のクラウド内で非人間のアイデンティティ(NHI)の数を静かに増加させています。
その人口はすでに企業を圧倒しています。多くの企業は現在、人間ユーザー1人に対して少なくとも45の機械アイデンティティを扱っています。サービスアカウント、CI/CDボット、コンテナ、AIエージェントはすべて、他のシステムに安全に接続して作業を行うために、APIキー、トークン、証明書の形で秘密情報を必要とします。GitGuardianのState of Secrets Sprawl 2025レポートは、この拡散のコストを明らかにしています。2024年だけで2,370万以上の秘密情報が公開GitHubに現れました。さらに、Copilotを有効にしたリポジトリは、秘密情報の漏洩を40%頻繁に引き起こしました。
NHIは人間ではありません#
システムにログインする人間とは異なり、NHIには資格情報のローテーションを義務付けるポリシーや、権限の厳密な範囲設定、未使用アカウントの廃止を義務付けるポリシーがほとんどありません。管理されないままでは、攻撃者がそれらの秘密情報が存在することを誰も覚えていない後でも悪用できる、高リスクの接続の密集した不透明なネットワークを形成します。
特に大規模言語モデルや検索強化生成(RAG)の採用は、このリスクを引き起こす拡散が発生する速度と量を劇的に増加させました。
LLMによって駆動される内部サポートチャットボットを考えてみましょう。開発環境への接続方法を尋ねられたとき、ボットは有効な資格情報を含むConfluenceページを取得するかもしれません。チャットボットは、正しい質問をする誰にでも秘密情報を無意識に公開する可能性があり、ログはアクセス権を持つ誰にでもこの情報を漏らす可能性があります。さらに悪いことに、このシナリオでは、LLMは開発者にこのプレーンテキストの資格情報を使用するよう指示しています。セキュリティの問題はすぐに積み重なります。
しかし、状況は絶望的ではありません。実際、NHIと秘密情報管理に関する適切なガバナンスモデルが実施されれば、開発者は実際に革新し、より速く展開することができます。
AI関連のNHIリスクを低減するための5つの実行可能なコントロール
AI駆動のNHIのリスクを管理しようとする組織は、次の5つの実行可能なプラクティスに焦点を当てるべきです:
- データソースの監査とクリーンアップ
- 既存のNHI管理の集中化
- LLM展開における秘密情報漏洩の防止
- ログセキュリティの向上
- AIデータアクセスの制限
これらの各分野を詳しく見てみましょう。
データソースの監査とクリーンアップ#
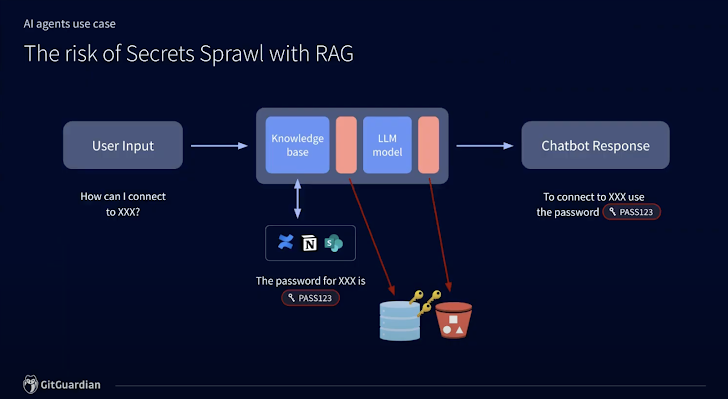
最初のLLMは、訓練された特定のデータセットにのみ結びつけられており、限られた能力を持つ珍しいものでした。検索強化生成(RAG)エンジニアリングは、必要に応じてLLMが追加のデータソースにアクセスできるようにすることでこれを変えました。残念ながら、これらのソースに秘密情報が存在する場合、関連するアイデンティティは悪用されるリスクにさらされます。
プロジェクト管理プラットフォームのJira、Slackのようなコミュニケーションプラットフォーム、Confluenceのようなナレッジベースなどのデータソースは、AIや秘密情報を念頭に置いて構築されていません。誰かがプレーンテキストのAPIキーを追加した場合、これが危険であることを警告する保護策はありません。チャットボットは、適切なプロンプトがあれば簡単に秘密情報を漏洩するエンジンになり得ます。
LLMがこれらの内部秘密情報を漏洩しないようにする唯一の確実な方法は、存在する秘密情報を排除するか、少なくともそれらが持つアクセスを取り消すことです。無効な資格情報は、攻撃者からの即時のリスクを伴いません。理想的には、AIがそれを取得する前に、これらの秘密情報のインスタンスを完全に削除することができます。幸いなことに、GitGuardianのようなツールやプラットフォームが、このプロセスをできるだけ簡単にする手助けをしてくれます。
既存のNHI管理の集中化#
「測定できないものは改善できない」という言葉は、最もよくロード・ケルヴィンに帰されます。これは非人間のアイデンティティガバナンスに非常に当てはまります。現在持っているすべてのサービスアカウント、ボット、エージェント、パイプラインを把握しない限り、エージェントAIに関連する新しいNHIに効果的なルールやスコープを適用する希望はほとんどありません。
これらの非人間のアイデンティティのすべてに共通する唯一のことは、すべてが秘密を持っていることです。NHIをどのように定義するかにかかわらず、私たちはすべて認証メカニズムを同じ方法で定義します:秘密です。このレンズを通してインベントリを集中させると、秘密の適切な保管と管理に焦点を絞ることができ、これは新しい懸念ではありません。
これを実現可能にするツールはたくさんあります。たとえば、HashiCorp Vault、CyberArk、AWS Secrets Managerなどです。すべてが集中管理され、把握されれば、長期間の資格情報の世界から、ポリシーによって自動化され、強制されるローテーションの世界に移行できます。
LLM展開における秘密情報漏洩の防止#
モデルコンテキストプロトコル(MCP)サーバーは、エージェントAIがサービスやデータソースにアクセスするための新しい標準です。以前は、AIシステムをリソースにアクセスさせるために、自分で接続を構成しながら進める必要がありました。MCPは、AIが標準化されたインターフェースを持つサービスプロバイダーに接続できるプロトコルを導入しました。これにより、開発者が統合を機能させるために資格情報をハードコードする可能性が減少します。
GitGuardianのセキュリティ研究者が発表した最も警戒すべき論文の1つでは、見つけたすべてのMCPサーバーの5.2%が少なくとも1つのハードコードされた秘密を含んでいたことが判明しました。これは、公開リポジトリで観察された秘密の露出率4.6%よりも顕著に高いです。
他の技術を展開する場合と同様に、ソフトウェア開発ライフサイクルの初期段階での少量の保護策が、後の多くのインシデントを防ぐことができます。機能ブランチにあるときにハードコードされた秘密をキャッチすることで、それがマージされて本番環境に出荷されることはありません。Gitフックやコードエディタ拡張を通じて開発者のワークフローに秘密検出を追加することで、プレーンテキストの資格情報が共有リポジトリに到達することはありません。
ログセキュリティの向上#
LLMは、リクエストを受けて確率的な回答を返すブラックボックスです。基礎となるベクトル化を調整することはできませんが、出力が期待通りであるかどうかを伝えることはできます。AIエンジニアや機械学習チームは、システムを調整してAIエージェントを改善するために、初期プロンプト、取得されたコンテキスト、生成された応答のすべてをログに記録します。
プロセスのいずれかのログステップで秘密が露出した場合、同じ漏洩した秘密の複数のコピーが、ほとんどの場合サードパーティのツールやプラットフォームに存在することになります。ほとんどのチームは、調整可能なセキュリティコントロールなしでクラウドバケットにログを保存しています。
最も安全な方法は、ログが保存またはサードパーティに送信される前にサニタイズステップを追加することです。これを設定するには多少のエンジニアリング作業が必要ですが、GitGuardianのggshieldのようなツールが、任意のスクリプトからプログラム的に呼び出すことができる秘密スキャンで支援してくれます。秘密が削除されれば、リスクは大幅に減少します。
AIデータアクセスの制限#
あなたのLLMはCRMにアクセスするべきでしょうか?これは難しい質問であり、非常に状況に依存します。内部の営業ツールで、SSOの背後にロックされていて、配信を改善するためにメモを素早く検索できる場合は問題ないかもしれません。あなたのウェブサイトのフロントページにあるカスタマーサービスチャットボットの場合、答えは断固として「いいえ」です。
権限を設定する際に最小特権の原則に従う必要があるのと同様に、展開するAIに対しても最小アクセスの原則を適用する必要があります。革新の能力を早期に制限したくないため、AIエージェントにすべてにフルアクセスを許可する誘惑は非常に大きいです。アクセスをあまりに少なくすると、RAGモデルの目的が失われます。アクセスをあまりに多くすると、悪用やセキュリティインシデントを招きます。
開発者の意識を高める#
最初に始めたリストにはありませんが、これらのガイダンスは適切な人々に届けなければ無意味です。最前線にいる人々には、より効率的かつ安全に作業するためのガイダンスとガードレールが必要です。ここで提供できる魔法の技術ソリューションがあればいいのですが、実際にはAIを安全に大規模に構築し展開するには、人々が適切なプロセスとポリシーで同じページに立つ必要があります。
開発側の方には、この記事をセキュリティチームと共有し、組織でAIを安全に構築する方法についての意見を求めることをお勧めします。セキュリティの専門家の方には、これを開発者やDevOpsチームと共有し、AIがここにあり、それを構築し、それと共に構築する際に安全である必要があるという会話を進めることをお勧めします。
機械アイデンティティのセキュリティ確保はより安全なAI展開を意味する#
AI採用の次のフェーズは、非人間のアイデンティティを人間ユーザーと同じ厳格さと注意をもって扱う組織に属するでしょう。継続的な監視、ライフサイクル管理、強力な秘密ガバナンスが標準的な運用手順となる必要があります。今、安全な基盤を構築することで、企業はAIイニシアチブを自信を持って拡大し、インテリジェントオートメーションの完全な可能性を解き放つことができ、セキュリティを犠牲にすることはありません。
翻訳元: https://thehackernews.com/2025/05/ai-agents-and-nonhuman-identity-crisis.html