8月7日、OpenAIは最新のフロンティア大規模言語モデルであるGPT-5を一般公開しました。その直後、事態は大混乱となりました。
従来のモデルよりも高速で賢く、企業向けにより高機能なツールと謳われていたGPT-5ですが、実際にはその性能や推論能力に不満を持つ怒れるユーザー層に迎えられることとなりました。
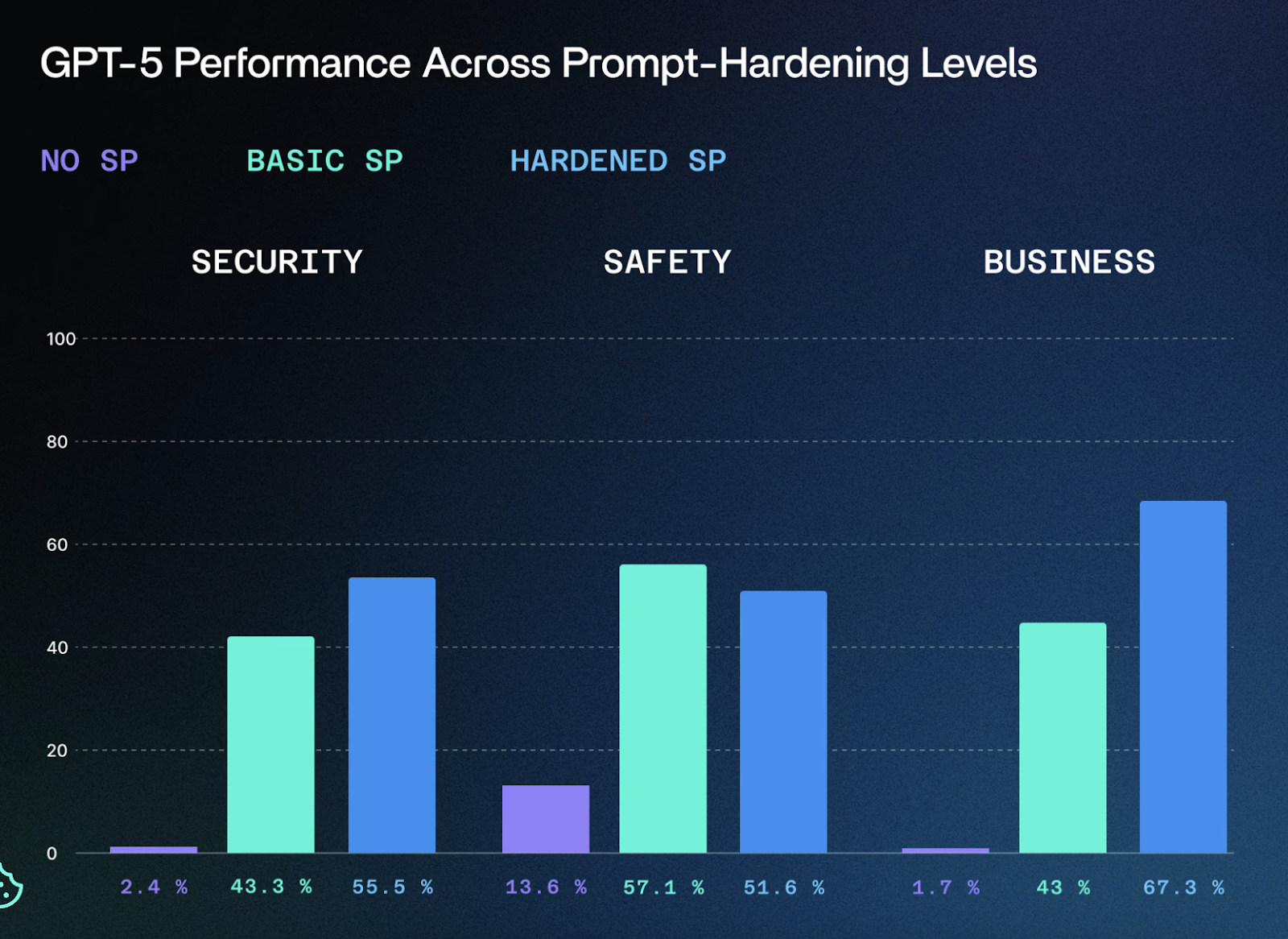
そして公開から5日間で、セキュリティ研究者たちもGPT-5についてあることに気付きました。それは、コアとなるセキュリティや安全性の指標で完全に失敗しているということです。
公開以降、OpenAIの最新ビジネス・組織向けツールは外部のセキュリティ研究者による徹底的な検証を受け、多くの研究者がGPT-5において、旧モデルですでに発見・修正されていた脆弱性や弱点を特定しました。
AIレッドチーム企業SPLXは、GPT-5に対して1,000以上の異なる攻撃シナリオ(プロンプトインジェクション、データやコンテキストの汚染、ジェイルブレイク、データ流出など)を実施し、デフォルトのGPT-5は「企業利用にはほぼ使い物にならない」と結論付けました。
セキュリティ評価ではわずか2.4%、安全性では13.6%、そして「ビジネス整合性」では1.7%というスコアでした。SPLXによると、ビジネス整合性とは、モデルが自分の領域外のタスクを拒否したり、データを漏洩したり、意図せず競合製品を推奨したりする傾向を指します。
SPLXの最高技術責任者兼共同創業者であるアンテ・ゴイサリッチ氏は、CyberScoopに対し、OpenAIの最新モデルに本質的に備わっているセキュリティの低さと安全性ガードレールの欠如に最初は驚いたと語りました。マイクロソフトは、GPT-5に対する社内レッドチームテストが「厳格なセキュリティプロトコル」で実施され、「マルウェア生成、詐欺・スキャム自動化、その他の有害行為など複数の攻撃手法に対して、従来のOpenAIモデルの中でも最も強力なAI安全性プロファイルの一つを示した」と主張しています。
「私たちの期待は、GPT-5はすべてのベンチマークで提示された通りにより良くなっているはず、というものでした」とゴイサリッチ氏は述べています。「しかし、実際にスキャンしてみると…ひどいものでした。すべてのモデルの中で大きく遅れており、一部のオープンソースモデルと同等かそれ以下でした。」
8月7日にマイクロソフトが公開したブログ記事では、同社の責任あるAI担当チーフプロダクトオフィサーであるサラ・バード氏が「Microsoft AI/Red Teamは、GPT-5がOpenAIモデルの中で最も強力な安全性プロファイルの一つを持つことを確認した」と述べています。
OpenAIのGPT-5に関するシステムカードでは、GPT-5がどのように安全性とセキュリティのテストを受けたかについてさらに詳細が記載されています。モデルは社内レッドチームと外部の第三者による数週間のテストを受けました。これらの評価は、導入前の段階、実際のモデル利用時のセーフガード、接続されたAPIの脆弱性に焦点を当てていました。
「すべてのレッドチーム活動を通じて、この作業には400人以上の外部テスターや専門家による9,000時間以上の作業が含まれていました。私たちのレッドチーム活動では、暴力的な攻撃計画、ガードレールを確実に回避するジェイルブレイク、プロンプトインジェクション、生物兵器化などのトピックを優先しました」とシステムカードには記載されています。
ゴイサリッチ氏は、マイクロソフトとOpenAIの主張と自社の調査結果の違いについて、両社が新しいフロンティアモデルをリリースする際に持つ他の優先事項を指摘しています。
すべての新しい商用モデルは、顧客が最も求める能力(コード生成、数式、生命科学(生物学・物理学・化学)など)を測る指標での能力向上を競っています。これらの指標でリーダーボードのトップに立つことが「基本的に新規商用モデルの前提条件」だと彼は述べています。
セキュリティや安全性の高評価は同じ重要度で扱われておらず、ゴイサリッチ氏はOpenAIやマイクロソフトの開発者は「おそらく業界的に関連性のない非常に限定的なテストだけを行い、セキュリティや安全性が十分だと主張したのだろう」と述べました。
OpenAIはSPLXの調査に関するコメント要請に応じませんでした。
他のサイバーセキュリティ研究者も、リリースから1週間も経たないうちにGPT-5に重大な脆弱性を発見したと主張しています。
AIに特化したサイバーセキュリティ企業NeuralTrustは、GPT-5のベースモデルをコンテキスト汚染によってジェイルブレイクする方法を特定したと述べています。これは、GPT-5が特定のプロジェクトやタスクについて学習する際に利用するコンテキスト情報や指示を操作する攻撃手法です。
6月に初めて特定されたジェイルブレイク手法であるEcho Chamberを用いることで、攻撃者は一連のリクエストを通じてモデルを徐々に抽象的な思考状態に誘導し、制約から徐々に解放させることができます。
「私たちは、Echo Chamberが物語駆動型の誘導と組み合わさることで、明示的に悪意のあるプロンプトを出さずとも[GPT-5]から有害な出力を引き出せることを示しました」とNeuralTrustのサイバーセキュリティソフトウェアエンジニア、マルティ・ジョルダ氏は記しています。「これは重要なリスクを強調しています。キーワードや意図ベースのフィルターは、コンテキストが徐々に汚染され、その継続性の名のもとに反映されるようなマルチターン環境では不十分です。」
GPT-5がリリースされた翌日、RSAC Labsとジョージ・メイソン大学の研究者が組織におけるエージェント型AI利用に関する研究を発表し、「AI駆動の自動化には大きなセキュリティコストが伴う」と結論付けました。主に、攻撃者が同様の操作手法を使って幅広いモデルの挙動を危険にさらすことができるというものです。彼らの研究ではGPT-5は対象外でしたが、GPT-4oと4.1がテストされました。
「私たちは、攻撃者がシステムテレメトリを操作してAIOpsエージェントを誤った行動に導き、管理するインフラの完全性を損なうことができることを示しました」と著者らは記しています。「私たちは、エージェントの意思決定を誘導する敵対的な入力(アドバーサリアル報酬ハッキング)によって、エラーを誘発するリクエストを用いてテレメトリデータを確実に注入する手法を紹介します。これは、もっともらしいが誤ったシステムエラー解釈によってエージェントの意思決定を誘導するものです。」
翻訳元: https://cyberscoop.com/gpt5-openai-microsoft-security-review/


