
サイバーセキュリティ研究者は、TokenBreakと呼ばれる新しい攻撃手法を発見しました。これにより、大規模言語モデル(LLM)の安全性とコンテンツモデレーションのガードレールを単一の文字変更で回避することができます。
“TokenBreak攻撃は、テキスト分類モデルのトークン化戦略を標的にして偽陰性を誘発し、実装された保護モデルが防ぐために設置された攻撃に対してエンドターゲットを脆弱にします。”とKieran Evans、Kasimir Schulz、Kenneth YeungがThe Hacker Newsと共有したレポートで述べました。
トークン化は、LLMが生のテキストをその基本単位、つまりトークンに分解するために使用する基本的なステップです。これらはテキストのセットで見つかる一般的な文字列です。そのため、テキスト入力は数値表現に変換され、モデルに供給されます。
LLMはこれらのトークン間の統計的関係を理解し、トークンのシーケンス内で次のトークンを生成します。出力トークンは、トークナイザーの語彙を使用して対応する単語にマッピングされ、人間が読めるテキストにデトークン化されます。
HiddenLayerによって考案された攻撃手法は、テキスト分類モデルの悪意のある入力を検出し、安全性、スパム、またはコンテンツモデレーションに関連する問題をフラグする能力を回避するためにトークン化戦略を標的にしています。
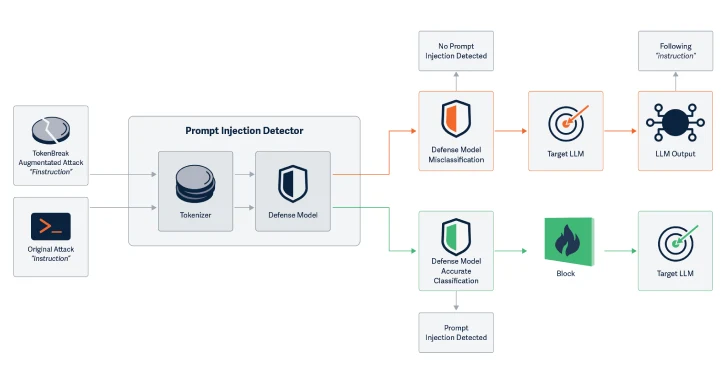
具体的には、AIセキュリティ企業は、特定の方法で文字を追加して入力単語を変更することで、テキスト分類モデルが破壊されることを発見しました。
例としては、「instructions」を「finstructions」に、「announcement」を「aannouncement」に、「idiot」を「hidiot」に変更することが挙げられます。これらの小さな変更により、トークナイザーはテキストを異なる方法で分割しますが、意味はAIと読者の両方にとって明確なままです。
この攻撃が注目されるのは、操作されたテキストがLLMと人間の読者の両方に完全に理解可能であり、未変更のテキストが入力として渡された場合と同じ応答をモデルが引き出すことです。
操作をモデルの理解能力に影響を与えない方法で導入することで、TokenBreakはプロンプトインジェクション攻撃の可能性を高めます。
“この攻撃手法は、特定のモデルが不正確な分類を行うように入力テキストを操作します。”と研究者たちは付随する論文で述べています。”重要なのは、エンドターゲット(LLMまたはメール受信者)が操作されたテキストを理解し、応答できるため、保護モデルが防ぐために設置された攻撃に対して脆弱であることです。”

この攻撃は、BPE(バイトペアエンコーディング)またはWordPieceトークン化戦略を使用するテキスト分類モデルに対して成功することが確認されていますが、Unigramを使用するものには成功しません。
“TokenBreak攻撃手法は、入力テキストを操作することでこれらの保護モデルを回避できることを示しています。これにより、製品システムが脆弱になります。”と研究者たちは述べています。”基盤となる保護モデルのファミリーとそのトークン化戦略を知ることは、この攻撃に対する脆弱性を理解するために重要です。”
“トークン化戦略は通常、モデルファミリーと関連しているため、簡単な緩和策が存在します:Unigramトークナイザーを使用するモデルを選択してください。”
TokenBreakに対抗するために、研究者たちは可能であればUnigramトークナイザーを使用し、バイパストリックの例でモデルを訓練し、トークン化とモデルロジックが一致していることを確認することを提案しています。また、誤分類を記録し、操作を示唆するパターンを探すことも役立ちます。
この研究は、HiddenLayerがモデルコンテキストプロトコル(MCP)ツールを利用して機密データを抽出する方法を明らかにしてから1ヶ月も経たないうちに発表されました:”ツールの機能内に特定のパラメータ名を挿入することで、システムプロンプト全体を含む機密データを抽出し、流出させることができます。”と同社は述べました。
この発見はまた、Straiker AI Research(STAR)チームが、バックロニムを使用してAIチャットボットを脱獄し、望ましくない応答を生成させることができることを発見した際にも発表されました。これには、暴言、暴力の助長、性的に露骨なコンテンツの生成が含まれます。
Yearbook Attackと呼ばれるこの手法は、Anthropic、DeepSeek、Google、Meta、Microsoft、Mistral AI、OpenAIのさまざまなモデルに対して効果的であることが証明されています。
“彼らは日常のプロンプトのノイズに溶け込んでいます—ここでは風変わりななぞなぞ、そこでは動機付けの頭字語—そしてそのため、モデルが危険な意図を見つけるために使用する鈍いヒューリスティックをしばしば回避します。”とセキュリティ研究者のAarushi Banerjeeは述べました。
“「友情、団結、配慮、親切」といったフレーズは、何の警告も発しません。しかし、モデルがパターンを完了する頃には、すでにペイロードが提供されており、これがこのトリックを成功させる鍵です。”
“これらの方法は、モデルのフィルターを圧倒するのではなく、その下をすり抜けることで成功します。彼らは完了バイアスとパターンの継続性、そしてモデルが意図分析よりも文脈の一貫性を重視する方法を利用しています。”
翻訳元: https://thehackernews.com/2025/06/new-tokenbreak-attack-bypasses-ai.html