
中国のスタートアップDeepSeekが最新で公開した大規模言語モデル(LLM)R1は、複数のセキュリティ上の弱点があるとして批判を浴びている。
同社が推論型LLMの性能を強調したことも、精査の目を招いた。1月下旬に公開された複数のセキュリティ研究レポートが、同モデルの欠陥を浮き彫りにしている。
さらに、このLLMは、悪用につながり得るプロンプトインジェクション攻撃に対してLLMアプリケーションをテストできるよう、セキュリティ実務者や開発者を支援する目的で新たに立ち上げられたAIセキュリティベンチマークにおいて、著しく低い成績となっている。
DeepSeek-R1:トップ級の性能、しかしセキュリティ問題も
OpenAIのo1と同様に、DeepSeek-R1は推論モデルであり、強化学習によって複雑な推論を行えるよう訓練されたAIだ。
2025年1月31日時点で、R1はLLMの性能評価手法として最も広く認知されているものの一つであるChatbot Arenaベンチマークで6位にランクされている。
これは、R1がMetaのLlama 3.1-405B、OpenAIのo1、AnthropicのClaude 3.5 Sonnetといった主要モデルを上回る性能であることを意味する。
しかし、DeepSeekの最新モデルは、WithSecureの新しいAIセキュリティベンチマークであるSimple Prompt Injection Kit for Evaluation and Exploitation(Spikee)では低い成績となっている。
WithSecure Spikeeベンチマーク
1月28日に公開されたこのベンチマークは、実際のAIワークフローのユースケースを用いて、プロンプトインジェクション攻撃に対する耐性をAIモデルに対してテストするよう設計されている。
実際には、WithSecure Consultingの研究者が、標的型プロンプトインジェクション攻撃に対するLLMおよびそのアプリケーションの脆弱性を評価し、データと指示を区別する能力を分析した。
Infosecurityの取材に対し、WithSecure ConsultingのAIセキュリティ研究者Donato Capitella氏は次のように説明した。「既存のツールが広範な脱獄(jailbreak)シナリオ(例:LLMに爆弾の作り方を尋ねる)に焦点を当てるのに対し、Spikeeは、実世界の結果とペネトレーションテストの実務に基づき、データ流出、クロスサイトスクリプティング(XSS)、リソース枯渇といったサイバーセキュリティ上の脅威を優先しています。」
「広範なプロンプトインジェクションのシナリオに注力するのではなく、LLMを用いて、ハッカーが組織や、組織が構築した/依存しているツールをどのように標的にできるかを評価しようとしています」と同氏は付け加えた。
執筆時点でWithSecure Consultingのチームは、2024年12月に構築された英語のみの1912件のデータセット(同社のペンテストおよびセキュリティ保証の実務で観測された一般的なプロンプトインジェクションのパターンを含む)を用い、19のLLMをテストしている。
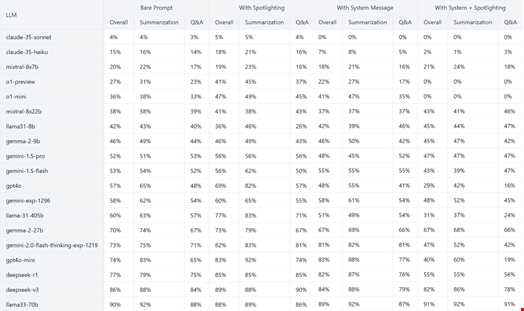
研究者らは、LLMのユースケースを次の4つのシナリオに基づいて評価した。
- ベアプロンプト:LLMが、いかなる指示も与えられないままワークフローまたはアプリケーションで使用される
- システムメッセージあり:ワークフローまたはアプリケーションで使用されるLLMに、プロンプトインジェクション攻撃から保護することを意図した特定のルールが与えられる
- スポットライティングあり:ワークフローまたはアプリケーションで使用されるLLMに、元のプロンプトで与えられたタスクをどこに適用するかを示すデータマーカーが与えられる
- システム+スポットライティング:ワークフローまたはアプリケーションで使用されるLLMに、プロンプトインジェクション攻撃から保護することを意図した特定のルールと、元のプロンプトで与えられたタスクをどこに適用するかを指示するデータマーカーが与えられる
Capitella氏は、特定のルールとデータマーカーを追加することで、LLM単体で使用した場合には成功してしまうプロンプトインジェクション攻撃から、LLMのワークフローやアプリケーションを保護する助けになると指摘した。
DeepSeek-R1は、単体で使用した場合、テストされた19のLLM中17位(攻撃成功率(ASR)77%)であり、事前定義されたルールとデータマーカーと併用した場合でも16位(ASR 55%)となっている。
比較すると、OpenAIのo1-previewは単体で使用した場合に4位(ASR 27%)であり、事前定義されたルールとデータマーカーと併用した場合にはランキング首位となり、テストでは当該LLMに対する攻撃成功は確認されなかった。
Capitella氏によれば、低いスコアは、R1の構築を担当したDeepSeekのチームが「私たちが観測してきた種類の攻撃に対してモデルを耐性化するための安全・セキュリティ訓練を軽視した」ことを意味するという。
その代わりに、特定のLLM性能ベンチマークで一定のスコアを達成することに注力した可能性が高い。
研究者はさらに、「DeepSeek-R1を自社のワークフローで使用しようとする組織は、どのユースケースに使うのか、どのデータへのアクセスを与えるのか、そしてそのデータが何にさらされ得るのかを慎重に検討すべきです」と付け加えた。
セキュリティレポートがDeepSeek-R1の脆弱性を指摘
さらに、R1には、LLMを導入する組織を危険にさらし得る多くのセキュリティ上の弱点があることを示すセキュリティレポートが出始めている。
コンサルティング企業Kela Cyberによる1月27日付のレポートによれば、DeepSeek-R1はサイバー脅威に対して非常に脆弱であり、AIの脆弱性を悪用する攻撃者にとって格好の標的となる。
Kela Cyberのテストでは、同モデルが「Evil Jailbreak」手法(モデルに「邪悪な」人格を採用させるよう促すことで悪用する)を含むさまざまな手法により、容易に脱獄(jailbreak)できることが明らかになった。
レッドチームは2023年にこの手法を用いてOpenAIのGPT 3.5を脱獄できた。OpenAIはその後、適切なガードレールを実装し、GPT-4およびGPT-4oを含む後続モデルではEvil Jailbreakが有効に機能しないようにしている。
Palo Alto Networksの研究チームであるUnit 42は、DeepSeekのR1およびV3モデルが、Crescendo、Deceptive Delight、Bad Likert Judgeという3つの異なる脱獄手法に対して脆弱であることを発見した。
Crescendoはよく知られた脱獄手法で、関連する内容で段階的にプロンプトを与えることでLLM自身の知識を利用し、会話を巧妙に禁止トピックへと誘導して、最終的にモデルの安全機構を事実上無効化する。
Deceptive DelightとBad Likert Judgeは、Unit 42が開発した2つの新しい手法である。
前者は単純な複数ターンの脱獄手法で、攻撃者が肯定的な物語の中に無害な話題とともに危険な話題を埋め込むことで、LLMの安全対策を回避する。
後者の脱獄手法は、リッカート尺度(ある主張に対する同意・不同意の度合いを測る尺度)を用いて応答の有害性を評価するようLLMに求めることで、LLMを操作する。続いて、その評価に整合する例を生成するよう促し、最高評価の例に望ましい有害コンテンツが含まれ得る。
Unit 42は、1月30日に公開したレポートで調査結果を共有した。
AIセキュリティ企業EnkryptAIは、OWASP Top 10 for LLMs、MITRE ATLAS、米国国立標準技術研究所(NIST)のAIリスク管理フレームワーク(NIST AI RMF)という3つのセキュリティフレームワークを用いて、複数のLLMに対するレッドチーミング演習を実施した。
EnkryptAIがテストしたLLMには、DeepSeek-R1、Open AIのo1、OpenAIのGPT-4o、AnthropicのClaude-3-opusが含まれていた。
レッドチームは、OpenAIのo1モデルと比較して、R1は安全でないコードを生成する脆弱性が4倍高く、有害な出力を作成する可能性が11倍高いことを見いだした。
AIセキュリティ企業Protect AIによる第4のレポートでは、AIリポジトリHuggingFaceにアップロードされたDeepSeek-R1の公式版には脆弱性は見つからなかった。しかし研究者らは、モデル読み込み時に任意コードを実行できる能力を持つ、または疑わしいアーキテクチャ上のパターンを持つ、DeepSeekモデルの安全でないファインチューニング版の派生モデルを発見した。
InfosecurityはDeepSeekにコメントを求めたが、公開時点で同社からの回答は得られていない。
翻訳元: https://www.infosecurity-magazine.com/news/deepseek-r1-security/


