
フィッシングは、サイバーセキュリティの世界において最も根強い脅威の一つであり続けています。人間は疲弊し、注意が散漫になりがちで、他者を信頼しやすく、緊急性や権威に対して弱いという性質を持っています。どれだけ意識向上トレーニングを積んでも、こうした弱点を完全に克服することはできません。
セキュリティコミュニティはこの現実を概ね受け入れ、ユーザーがフィッシングの脅威に気づく前に遮断・ブロックできる自動検知システムの開発へと注力を移してきました。
しかし、攻撃者もここでの対策に適応してきています。近年のフィッシングキャンペーンでは、スキャナーには無害なコンテンツを返しながら実際の被害者には悪意あるページを表示する「クローキング技術」が多用されるようになっています。あるいは、自動化されたアクセス自体を完全にブロックする手法も使われています。こうして、人間の脆弱性を補うために構築してきた自動防御機能が、組織的に無力化されつつあるのです。
URLインフラへのアプローチ
東京都立大学の研究者たちは「PhishLumos」というシステムを開発しました。このシステムは、リダイレクトやアクセス不能なページ、欺瞞的なページ、空白ページをすべて不審なものとして扱い、コンテンツ分析には依存しないアプローチを採用しています。
その代わりに着目するのは、URLの基盤となるインフラです。具体的には、URLが解決するIPアドレス、他のドメインと共有するネットワーク接続、使用するSSL証明書、そして過去のスキャン記録に残された痕跡などが対象となります。
これにより、フィッシングキャンペーン全体の構造を再構築し、そこで使用されている他のURLを特定することが可能になります。さらに、キャンペーンの組織構造、関連アセット、各要素の相互関係を可視化するグラフも生成できます。
このグラフを活用して、専門化されたLLMエージェントの連携チームがキャンペーンのプロファイリングを行い、検証済みの検知ルールを生成します。
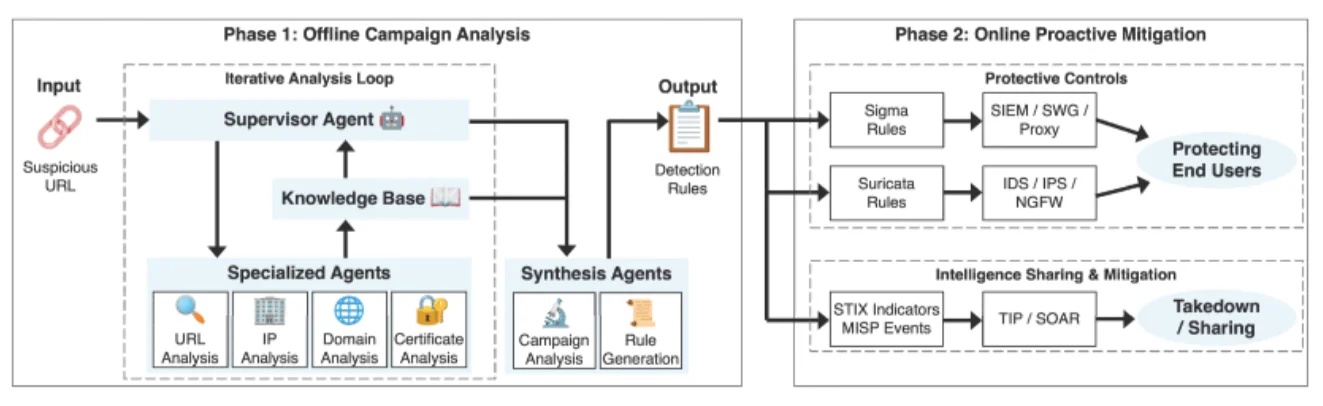
PhishLumosの2フェーズワークフロー(出典:IEEE)
実環境テストの結果
「103件の実際のキャンペーン(6,020件のURL)を対象としたテストでは、PhishLumosはキャンペーンカバー率の中央値100%を達成し、専門家による検証前の検知リードタイムの中央値は192.8時間(8.0日)を記録しました。また、1,000件の正常なURLに対する誤検知率はわずか0.1%でした」と研究者たちは報告しています。
「600件の難易度の高いシードURLを起点とした6か月間の実環境調査では、生成されたルールによって192,407件の追加URLが発見されました。そのうち92.0%は、マルチエンジンスキャンサービスにより、後に少なくとも1つのエンジンから悪意あるURLとして判定されました。」
PhishLumosは同一インフラを共有するURLの関連性を発見することで機能するため、攻撃者がインフラの使い回しを避けた場合(使い捨てインフラを使用する場合など)には対応が難しくなります。
研究者たちの実環境調査では、PhishLumosが与えられたシードURLのうち半数強に対して検知ルールを生成できた一方、残りのケースでは共有インフラが十分に存在せず、分析に限界がありました。
また、PhishLumosが参照する外部データソース(Webスキャン、パッシブDNS、証明書ログ)の品質にも依存します。これらのデータに欠落やブラインドスポットがあると、キャンペーンのマッピング精度が制限される可能性があります。
PhishLumosは既存の防御策を代替するものではなく、補完するものとして設計されています。分析結果が得られないケースでは、従来のURLスキャナーや人間のアナリストによる対応が引き続き必要です。
「PhishLumosは、少数の優先度の高いシードURLをトリアージするためのアナリスト向けオフラインツールです。リアルタイムの通信速度検査を想定した設計ではありません」と研究者たちは論文の中で説明しています。
「キャンペーンレベルという目標設定は、フィッシング作戦が実際にどのように組織され、脅威インテリジェンスが現場でどのように活用されるかと合致しています。PhishLumosはURLごとのラベルを返すのではなく、ハンティング、ブロッキング、テイクダウン申請、情報共有といったワークフローを直接支援する、再利用可能な対策アーティファクトを生成します。」
翻訳元: https://www.helpnetsecurity.com/2026/06/15/phishlumos-phishing-campaign-detection/


