
Meta Superintelligence Labsは、ツール使用、視覚的思考の連鎖、マルチエージェントオーケストレーションをサポートするネイティブマルチモーダル推論モデルであるMuse Sparkを発表しました。このリリースには、段階的にロールアウトされており、複数のエージェントが並列に推論するようにオーケストレーションするContemplating modeが含まれています。
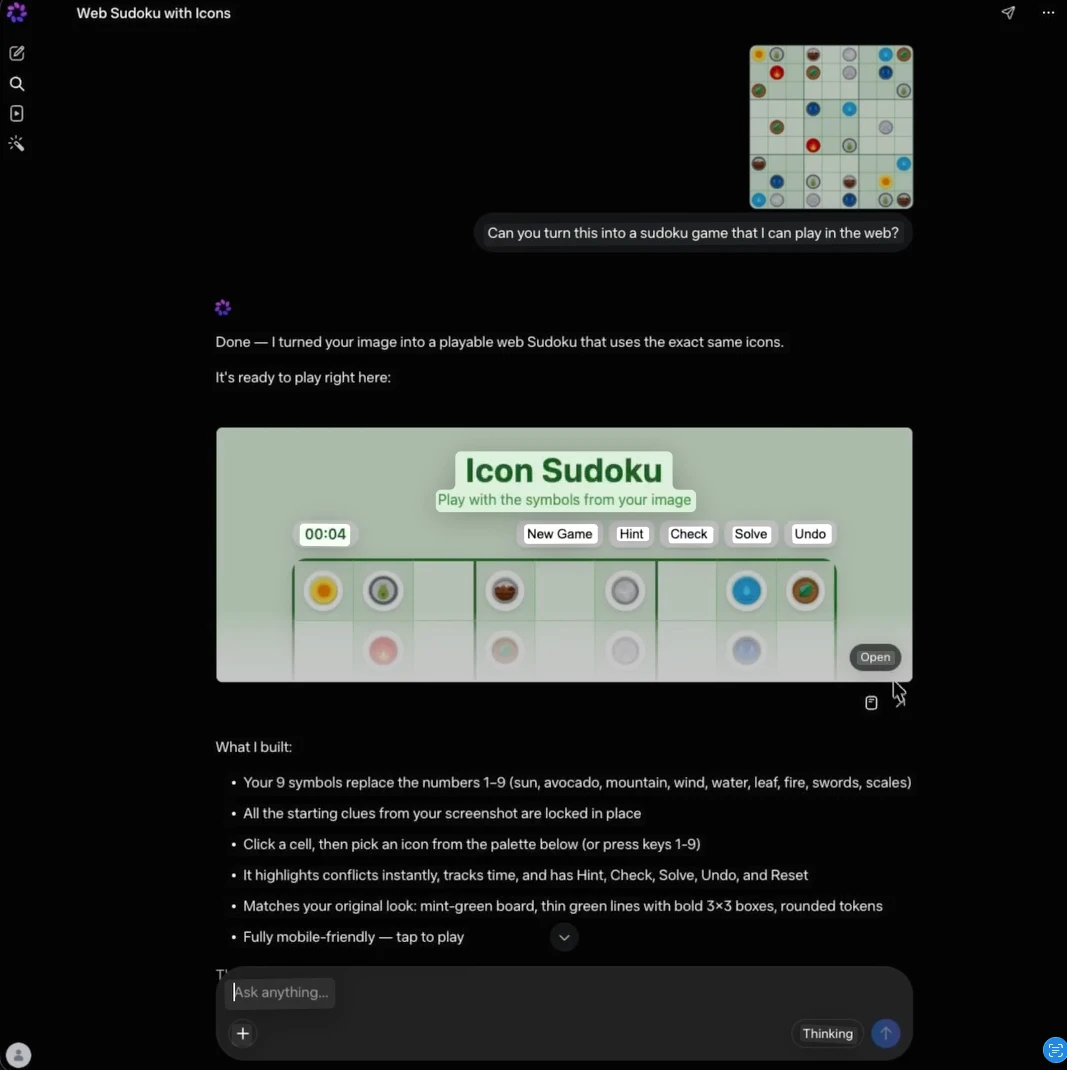
プロンプト:これをウェブでプレイできるスドゥクゲームに変えることができますか?(出典:Meta)
機能
Metaは、ユーザーの世界を理解できる個人スーパーインテリジェンスへの推進の一部として、Muse Sparkを位置付けています。このモデルはユーザーの直近の環境を分析し、その推論能力を通じてウェルネス関連のユースケースをサポートできます。
このモデルはドメイン全体のツールに視覚情報を統合します。視覚的なSTEM質問、エンティティ認識、および位置特定で優れたパフォーマンスを発揮し、ミニゲームの作成や動的注釈を備えたホーム家電のトラブルシューティングなどのインタラクティブな体験を実現できます。
同社は、健康関連の応答を改善することを目的とした訓練データをキュレーションするために、1,000人以上の医師と協力したと述べています。このモデルは、栄養価や運動中の筋肉活動などの情報を説明するインタラクティブディスプレイを生成できます。
モデルスケーリング
Metaは、事前訓練、強化学習、およびテスト時推論の3つの軸にわたるMuse Sparkのスケーリングを研究しています。
事前訓練中、システムは後の段階の基礎として機能するマルチモーダル理解、推論、およびコーディング機能を開発します。
強化学習は能力を増幅し信頼性を向上させるために使用され、同社によれば、未見のタスクに一般化する利益があります。
テスト時推論により、システムは応答を生成する前に「考える」ことができます。Metaは、思考時間ペナルティを使用してトークン使用を最適化し、マルチエージェントオーケストレーションを使用して比較可能なレイテンシーを維持しながらパフォーマンスを向上させていると述べています。
「トークンあたりの最大インテリジェンスを提供するために、当社のRL訓練は思考時間のペナルティを受けた正確性を最大化します」と同社は述べています。
同社は、並列エージェントの数を増やすことにより、レイテンシーを大幅に増やさずに推論時により多くの推論が可能になると付け加えています。
安全性評価
Muse Sparkは、脅威モデル、評価プロトコル、および展開閾値を定義するMetaの高度なAIスケーリングフレームワークを使用して、展開前に評価されました。
同社によれば、このモデルは生物学的および化学的脅威などの高リスク領域での拒否動作を示します。Metaはまた、Muse Sparkはそのようなシナリオを実現するために必要な自律能力や有害な傾向を示さず、評価されたリスク領域全体で安全マージン内に留まっていると述べています。
翻訳元: https://www.helpnetsecurity.com/2026/04/09/meta-muse-spark-personal-superintelligence/


