
AIは職業生活と私生活の両方の一部になり、パーソナルコンピュータやインターネットよりも速く主流の採用に達しています。これらのシステムは現在、推論、安全性、および現実世界のタスクでテストされていますが、これらの測定の信頼性は不確実なままです。
スタンフォード大学の人間中心型人工知能研究所による2026年AIインデックスは、経済価値、労働市場への影響、およびAI主権の役割を含む、この成長を取り巻く広い環境を概説しています。また、科学と医学の発展、ベンチマークの飽和、および追い付くのに苦労しているガバナンスフレームワークも検討しています。グローバルセンチメントはこの状況を反映しており、楽観主義の高まりとともに継続的な懸念があります。
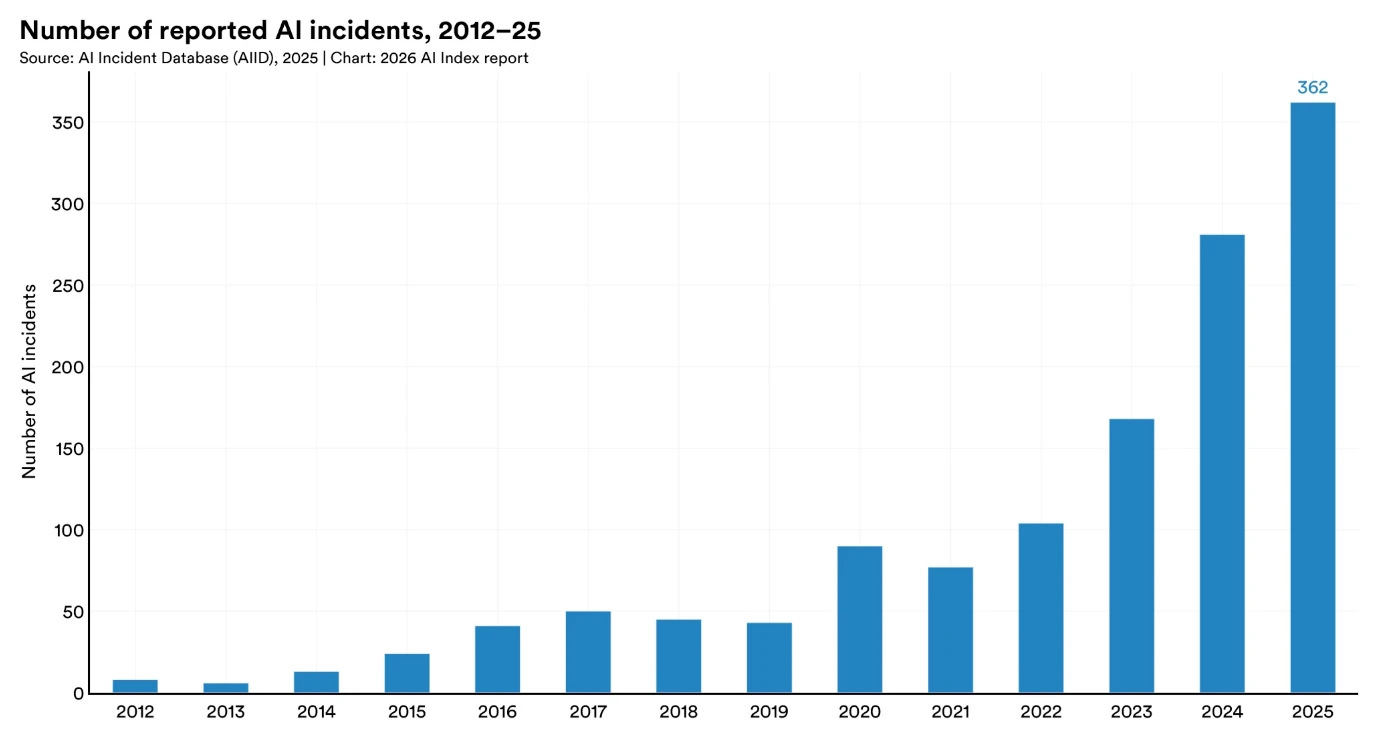
報告されたAIインシデント数、2012年~25年(出典:Stanford HAI)
インシデント記録は継続的に増加している
報告されたAIインシデント数は過去1年間で増加しており、これらのシステムが現実世界の環境に広がっていることを反映しています。AIインシデントデータベースは2025年に362件のインシデントを記録しており、2024年の233件から増加しています。OECDによる別の監視取り組みは同様のパターンを示しており、2026年初頭の月間インシデント数は435件に達し、最近の数ヶ月間は平均300件以上で推移しています。
これらの数字は、意図しない出力から悪用、および運用障害に至るまで、様々な問題をキャプチャしています。顧客向けチャネルまたは内部自動化パイプラインで動作するシステムは、小さなエラーが迅速に浮上し、複数の環境で観察される規模で動作するようになりました。報告はその露出を反映しており、デプロイメントが拡大するにつれて、より多くのケースが公開または半公開記録に入力されています。これらのシステムの監視を担当するチームは、トリアージ、分類、および対応が必要となる増加する信号量と共に作業しています。
多くの場合、これらのインシデントはソフトウェア環境で見られる慣れたパターンに従いません。出力はコンテキスト、入力フレーズング、または相互作用の履歴に応じて異なる場合があり、これは問題の再現と分析を難しくする可能性があります。これは、インシデント対応に複雑さを加え、チームは常に定義された失敗状態にきちんとマップしないシステム動作を解釈しなければなりません。
モデルアクセスがより制御されるようになっている
AIモデルのリリース方法は、制限されたアクセスへとシフトしています。最も注目すべきモデルは現在業界から提供されており、多くはユーザーがどのように相互作用するかを制限するAPIを通じて配信されています。2025年に追跡されたモデルの中で、APIベースのリリースが最も一般的なアプローチであり、組織がこれらのシステムをワークフローに統合する方法を形成しています。
トレーニングコードはめったに共有されません。ほとんどのモデルはそれらを構築するために使用されたコードなしでリリースされており、それのコードを公開で利用可能にするのはわずかな数です。これは外部チームが結果を再現したり、トレーニング方法を調査したり、その開発者によって定義された条件外でシステムをテストしたりする能力を制限します。また、歴史的に弱点や予期しない動作を特定する役割を果たしてきた独立した検証の範囲を狭めます。
限定されたアクセスはまた、組織がデプロイ前にベンダーとツールをどのように評価するかに影響を及ぼします。トレーニングプロセスまたはモデルアーキテクチャの可視性がなければ、評価はしばしば観察されたパフォーマンスと文書化された動作に焦点を当てます。これはシステムが使用中の統合テストと監視に、より多くの重みを置きます。
透明性スコアが低下している
ファウンデーションモデルの周囲の開示の全体的なレベルは低下しています。ファウンデーションモデル透明性インデックスは、2024年の平均スコア58から2025年の40に低下しました。低いスコアはモデルの構築方法およびデプロイ後に何が起こるかに結びついたカテゴリに現れ、データソース、計算リソース、および下流の影響を含みます。
これは、組織が採用するシステムをどのように評価するかに影響します。モデルにアクセスする方法に関する情報は、ドキュメンテーションとインターフェイスを通じてしばしば利用可能ですが、トレーニングデータ、システム上の制限、または長期的な影響に関する詳細はあまり開示されません。そのアンバランスは、リスク評価とガバナンスに必要な情報のギャップを残します。特にシステムが重要なプロセスに統合される場合です。
開示の削減はまた、表面的な機能を超えてシステムを比較する能力を制限します。チームは、モデル間の違いを理解するために部分的なドキュメンテーションまたはサードパーティの分析に依存する場合があり、これは選択とデプロイメント決定に不確実性をもたらす可能性があります。
能力テストは安全性テストよりも可視性が高い
モデル開発者は推論、コーディング、および一般的なタスクパフォーマンスを測定するベンチマークの結果を引き続き公開しています。これらの評価は広く使用されており、モデル間のシステム能力を比較するための一般的な参考ポイントを提供します。
安全性関連のベンチマークはあまり一貫して報告されず、モデルのセットが少なくなっています。有害な出力、バイアス、または悪用シナリオを調査するカテゴリは、より少ない開示に表示され、一貫した報告構造に欠けています。このアンバランスな報告は、能力ベンチマークが広く利用可能な場合でも、システムがリスク条件下でどのように動作するかに関してシステムを比較する能力を低下させます。実際には、AIシステムを評価するチームは、しばしば限定的な公開データと独自の内部テストを組み合わせます。
「技術的な最先端では、主導的なモデルはほぼ互いに区別がつきません。オープンウェイトモデルはこれまで以上に競争力があります。しかし、モデルが収束するにつれて、それらを評価するために使用されるツールは関連性を保つのに苦労しています。ベンチマークは飽和しており、フロンティアラボはより少なく開示されており、独立したテストは開発者が報告していることを常に確認していません」と、Yolanda GilおよびRaymond Perrault、AIインデックスレポート共同議長は述べています。
監視慣行は限定的な可視性に適応している
AIシステムは、本来自律的な意思決定または確率的な出力に対応するように設計されていないワークフローに統合されています。これにより、特にシステムがユーザーと相互作用し、コンテンツを生成し、または運用上の意思決定に影響を与える領域で、監視プロセスに新しい要求が生じます。
セキュリティとリスクチームは、継続的な監視と内部検証に対する強調をより加えることで適応しています。多くの場合、評価は公開されたベンチマークのみに依存しません。組織は、特定の条件の下でモデルがどのように動作するかを観察するための独自のテスト環境を構築しています。
チームは、ソフトウェアバグまたはセキュリティ脆弱性などのカテゴリに適合しないAI関連の問題を分類および対応するプロセスを開発しています。これらのインシデントは、曖昧な出力、予期しないモデル動作、または定義された失敗ポイントなしに意図しない結果を生成する相互作用を含む可能性があります。
ベンダーの関係もこれらの条件下で変化しています。基礎となるモデルの詳細へのアクセスが制限されている場合、組織は契約条件、使用制御、およびサービスレベルの期待に大きく依存して説明責任を定義します。これはモデルが統合後にどのように配置および監視されるかに対する重要性を高めますが、元々どのように開発されたかはあまり強調されません。
これらの調整は、AI システムが本番環境でどのように管理されるかの広い転換を反映しています。監視は、モデル設計への外部の可視性ではなく、内部管理と運用経験によって形成された、使用中のシステム動作に結びついた進行中のプロセスになりつつあります。
翻訳元: https://www.helpnetsecurity.com/2026/04/14/ai-adoption-safety-transparency-report/


