

人工知能はトレンドであり、テック企業が話題にしていることのすべてのようです。
また、これは完全に新しいものであるかのように見えます。
しかし、AIは1956年以来学問分野として存在しており、すでに1990年代までにチェスの大家を打ち負かしていました。今日、私たちが理解しているAIは、特定の問題ではなく汎用的な問題を解決できる技術的進歩である生成型AIです。それでも、生成型AIは人工知能という海の一滴に過ぎず、万能薬ではありません。
この記事はSysdigの複数のAIおよびセキュリティ専門家の知識から作成されました。彼らから、AIの全体像の概要を得て、AIとセキュリティが手を取り合ういくつかのケースを評価し、スプレッドシートだけでニューラルネットワークを作成する方法を発見します。
この記事はAIとセキュリティに関するシリーズの一部です:
AIはかつて複雑なアルゴリズムでした
著者:クリスタル・モリン、シニアサイバーセキュリティストラテジスト
私たちは、人工知能を、人間の知能をシミュレートするタスクを実行する複雑な計算と考えています。
この定義では、いくつかの厚いスプレッドシートは人工知能と見なされる可能性があり、それはいかに神秘化を解くのに素晴らしいか分かります。後でこの考えに戻ります。
より真摯に言えば、初期のAIはビデオゲームに見られます。敵が画面を横切って移動し、位置への道を見つけ、個性を与えるアルゴリズムは人工知能です。

1997年2月までに、IBMのディープブルーは、現役の世界チャンピオンであるガリー・カスパロフをいくつかのチェスゲームで打ち負かすことができました。これを達成することは、単に考えられるすべての結果のデータベースをクエリして最良のものを選択するだけではありませんでした。ディープブルーは毎秒2億回のチェスポジションを評価しましたが、キングを安全な位置に保つことがどの程度重要であるかなど、他のパラメータも考慮しました。
ディープブルーは、複雑なアルゴリズムの時代を告げ、現在もビデオゲーム、製造業の生産エラーを予測するため、または輸送ルートを計画するためのロジスティクスで使用されています。
AIは現在、統計に基づいています:ファジー論理とベイズ数学
著者:アレハンドロ・ビジャヌエバ、シニアスタッフプロダクトマネージャー
私たちの脳は複雑なアルゴリズムではなく、ファジー論理で機能します。生活は私たちの脳にとって黒と白、0か1かではありません。私たちにとって、入力と出力は不明確です。
私たちは緑と青が何であるかについても同意できません。「私のブルーはあなたのブルーですか」を指標としてチェックしてください。私は残りの人口よりもブルーと考える色を考慮しています:
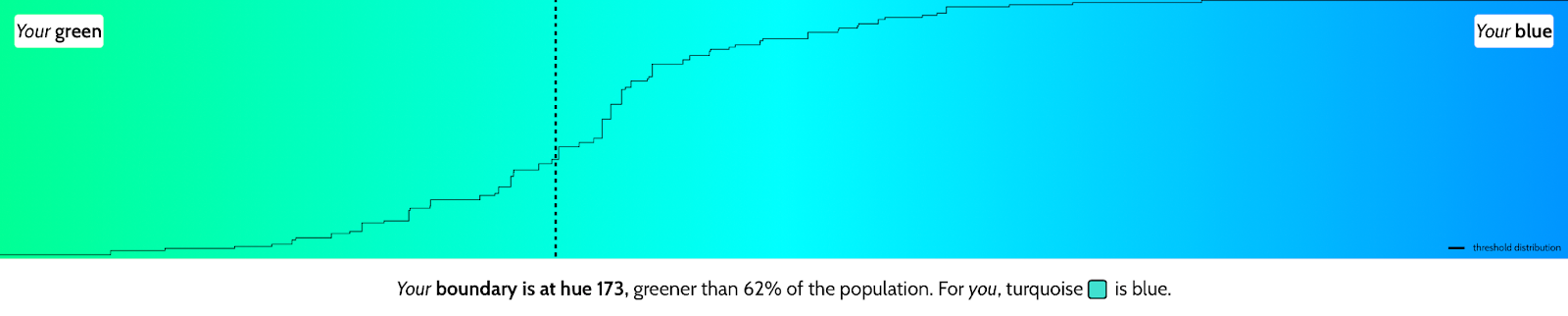
私たちはそれがトラであるかどうかを気にしません。私たちはまず走り、安全になったら再評価します。生き残るために、私たちはパターンを学ぶことに優れていて、異常を特定する必要があります。
コンピュータはこのあいまいさを統計を使ってレプリケートでき、ベイズプログラミングがそのための最初の技術の中にありました。
サイバーセキュリティにおける統計
著者:ミゲル・ヘルナンデス、シニアスレットリサーチエンジニア
例えば、ベイズスパムフィルタは、ジャンクメールに存在する単語または単語の組み合わせの確率分布を学びます。完全に新しいメールが与えられると、フィルタはそれがスパムである確率をスコアリングします。
SIEMやアンチウイルスソフトウェアのようなセキュリティツールは、統計を使ってシステムの一般的な動作をプロファイルし、異常な動作を特定します。これらのプロファイルは、悪意のあるバイナリにフラグを立てるためのプロセスのリスト、リソース使用量の急増を検出するためのメトリクス、または疑わしいネットワーク接続またはファイルアクセスを強調するためのリソースアクセスに基づくことができます。
初期のセキュリティテクノロジーが比較的単純な統計モデルに依存していた一方で、現在のソリューションは複雑な高次元データをモデル化するためにニューラルネットワークをますます使用しています。この進化により、以前に見たことのない脅威をより正確に検出でき、統計学習がAI駆動のサイバーセキュリティの基礎であり続けることを示しています。
AIの移動目標の呪い
著者:マテオ・ブリロ、プロダクトマネージャー
ディープブルーは当時の大きなマイルストーンでした。それは多くの人々にとって目覚めの呼び出しでした。突然、アイザック・アシモフの本とロボコップのような映画が実現していました。
しかし、現実はすぐに続きました。
複雑なアルゴリズムとベイズプログラミングがあまりにも単純で、具体的な問題を解決するためにのみ使用できることをどのように見ているかが分かります。
だから私たちは、少なくとも学術的には、それらを人工知能と見なすのをやめました。
これはAIの呪いです:私たちが脳をより理解し、コンピューティングがより進歩し、何かをAIとしてラベル付けする際により厳格になるほど。
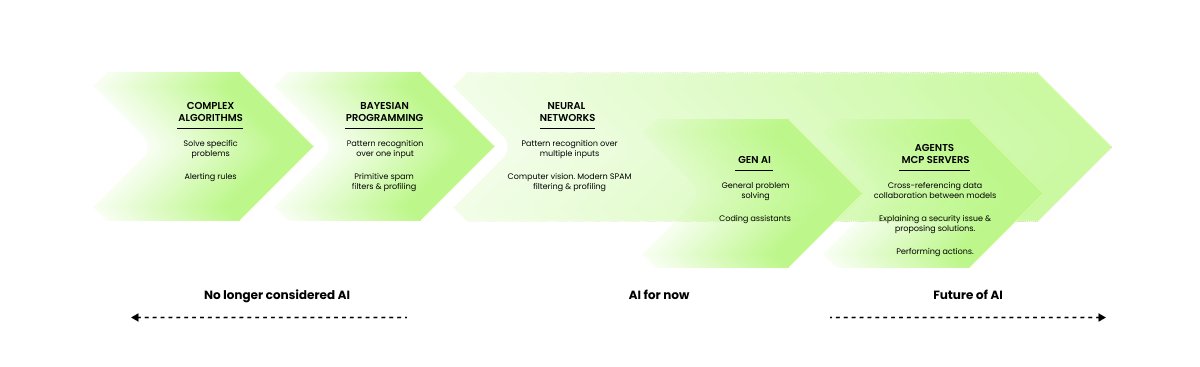
では、今はどこにいるのでしょうか?
それはすべてニューラルネットワークについてです
著者:ビクター・ヒメネス、コンテンツ貢献者。
人間の思考をシミュレートすることで成功したい場合は、生物学からいくつかのインスピレーションを得る必要があります。
例えば、ニューラルネットワークは数学を使ってニューロンが私たちの脳でどのように相互接続するかをモデル化します:
- それらはレイヤーに編成されたノードで構成されています。
- 各ノードの値は、前のレイヤーのノードの値の加重和です。
- 最初のレイヤーはネットワークの入力で構成され、最後のレイヤーは出力を表します。
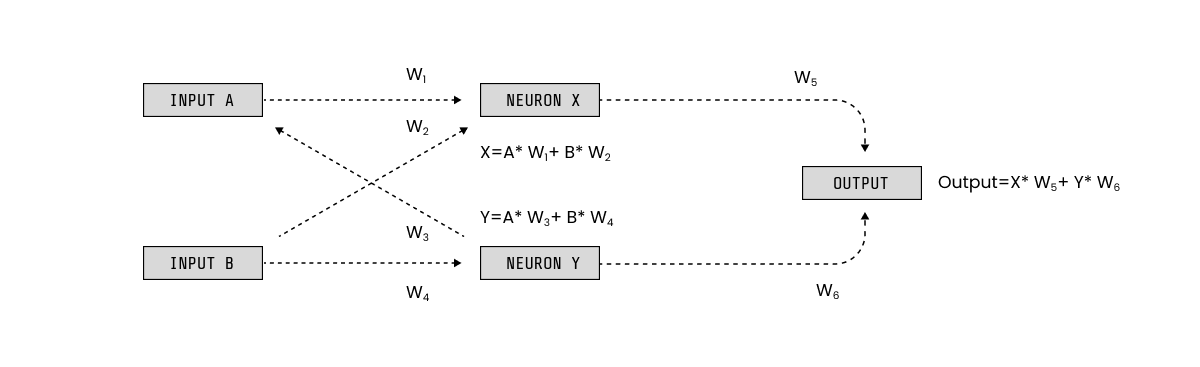
それは本当に加算と乗算の束と同じくらい単純です。しかし、それはそのような抽象的な概念であるため、それを実践にどのように置くかを見ることは簡単ではありません。
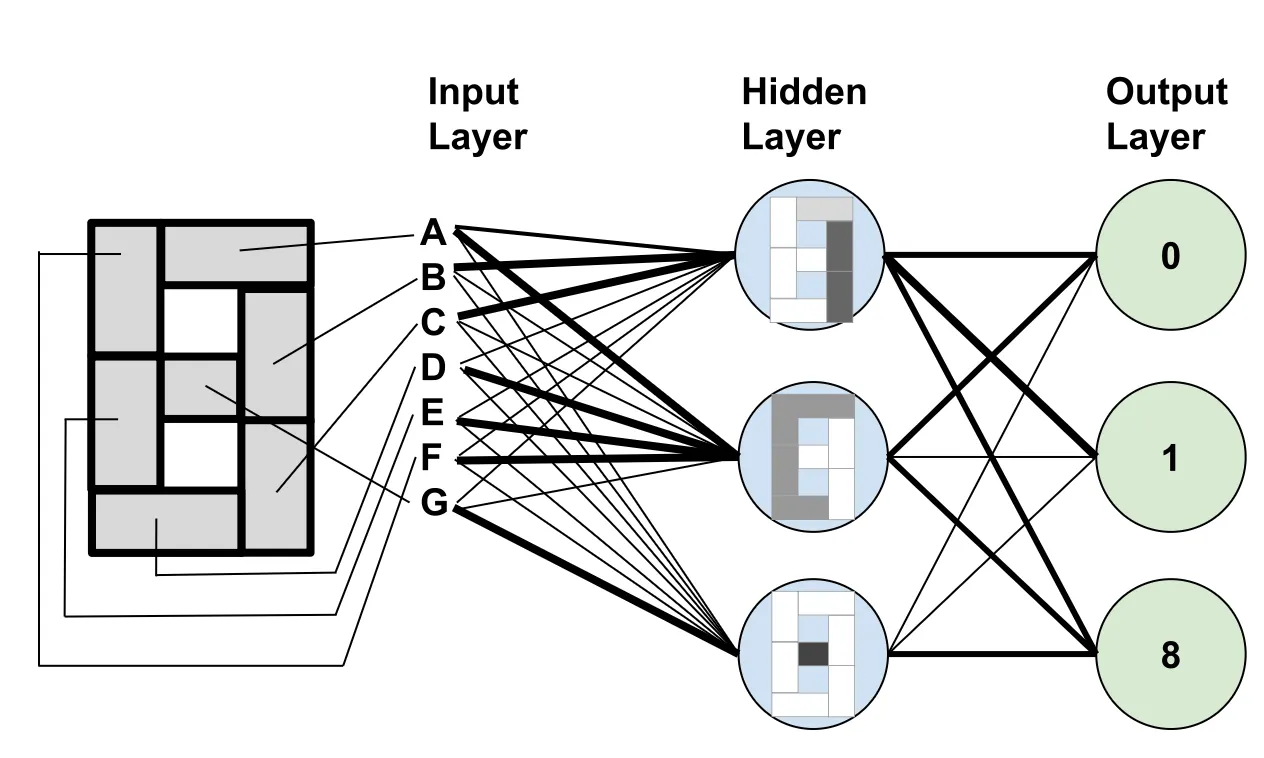
ですから、7セグメント表示で数字の0、1、8を検出できる非常にシンプルなニューラルネットワークを用意しました。この数学がすべてがいかに単純であるかを示すために、ダウンロードして遊べるシンプルなスプレッドシートを使用しました。
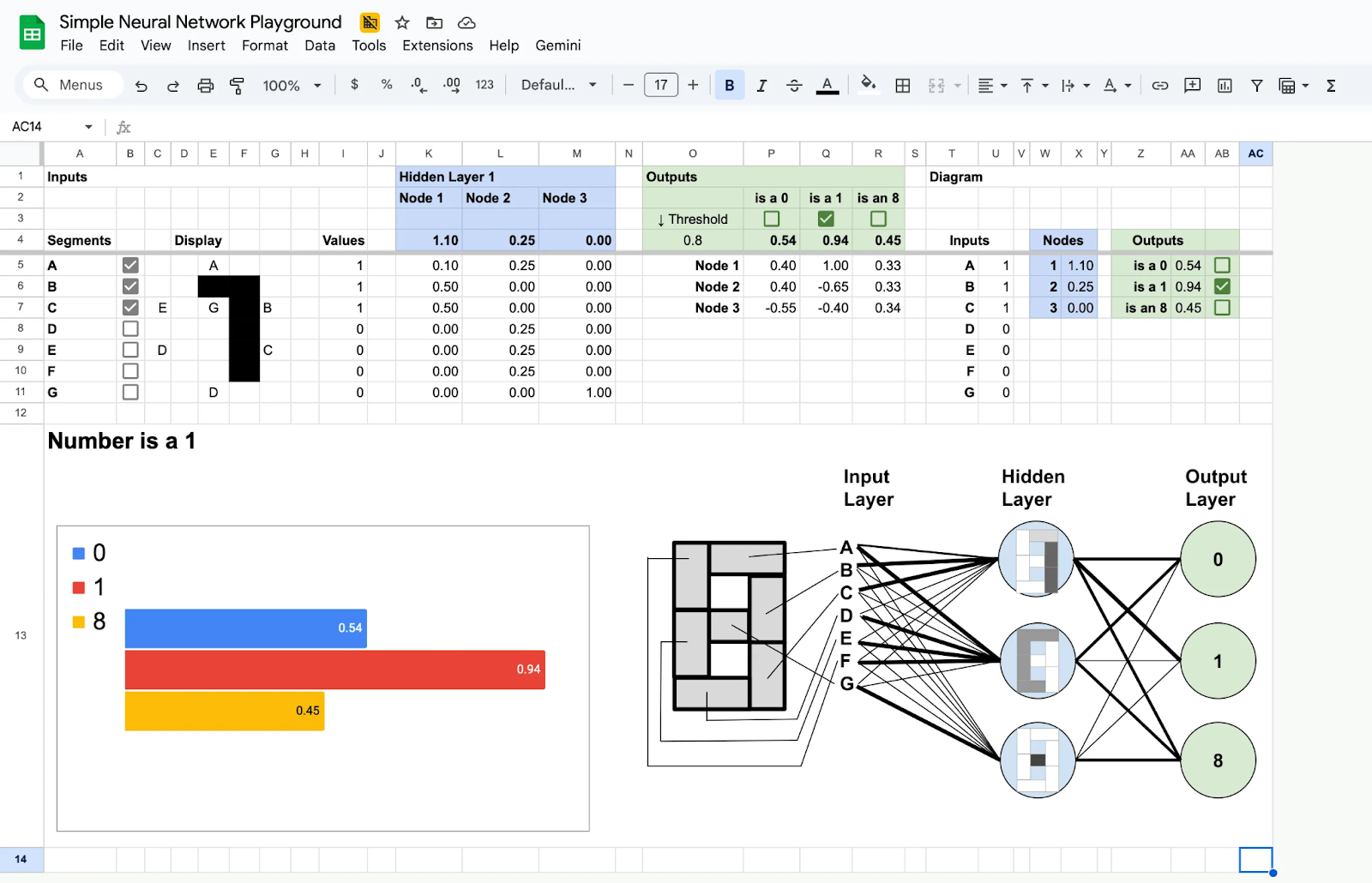
スプレッドシートを自分のペースで検査できるようにするための簡単なガイドをここに示します:
- 入力A〜Gは、表示上の特定のセグメントが点灯しているかどうかを示す0または1の値です。
- 隠れレイヤーは特定の特性を識別するために使用されます:
- 最初のノードは、セグメントA、B、Cに重みを割り当て、残りの入力を無視することで、スティックを検出します。
- 2番目のノードは、残りの周辺セグメントを検出します。
- 3番目のノードはミドルダッシュを検出します。
- 出力はこれらの機能を組み合わせて、表示されている数字を特定します:
- それはスティックと周辺セグメントを含むが、ダッシュを含まない場合はゼロです。
繰り返しになりますが、これらの加算と乗算(種類)よりも複雑になることはありません。適切なニューラルネットワークからの主な違いはノードの数量であり、それは数百万にもなります。
注:この数学(行列の乗算と加算)は3Dグラフィックスで使用されるものと同じです。そのため、グラフィックカードもAIコンピューティングに使用されています。
より現実的な例を見たい場合は、手書きの数字を検出できるこのニューラルネットワークシミュレーターをチェックしてください。手書きの数字を分類するニューラルネットワークを構築し、MNIST元のデータセットでそれをトレーニングするための多くのチュートリアルがあります。
待ってください、それをトレーニングしますか?
機械学習:ニューラルネットワークのトレーニング
著者:エマヌエラ・ザッコーネ、AIスタッフプロダクトマネージャー
ノードと重みの構造はニューラルモデルと呼ばれます。デジット検出器に使用したモデルは比較的単純で、重みを手動で割り当てることができました。
しかし、どのように数十億のノードを持つモデルを構築しますか?
さて、あなたはそれをトレーニングします。
その方法の1つは、遺伝的アルゴリズムを使用することです:
- ネットワーク構造から始めます。
- モデルのパフォーマンスを評価するためのスコアリングメトリックを定義します。それを適応度関数と呼びましょう。
- いくつかのランダムな重みを提供し、シミュレーションを実行します。
- 適応度関数を使用して、この世代から最も成功したモデルを選びます。
- ノード値をわずかに変更し、別のシミュレーションを実行します。
- 最も成功したものを選択し、わずかに変動させ、再度シミュレートし、数百回繰り返します。
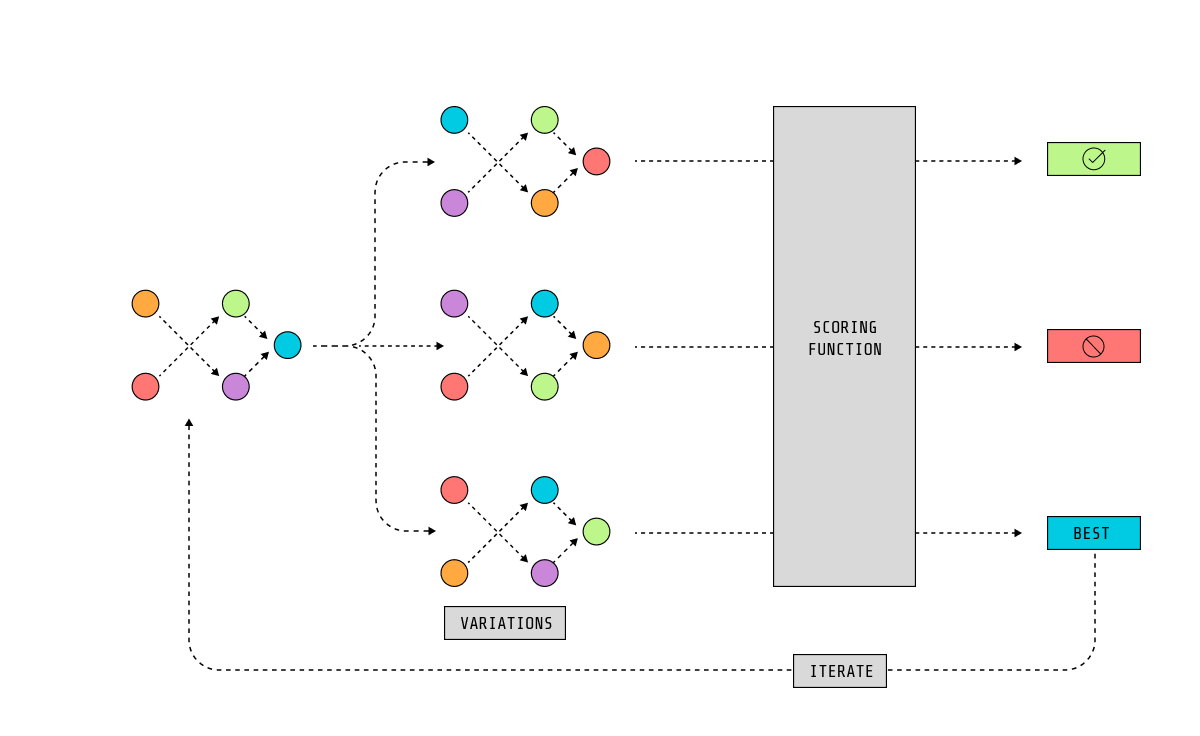
運が良ければ、数世代後に、あなたが求めているタスクを実行できるモデルで終わるでしょう。このシステムは自然選択がどのように最も適応した生物を選ぶかから着想を得ており、私たちが学ぶために使う試行錯誤プロセスを表しています。
このトレーニング方法は最適ではないことに注意してください。そのため、AIモデルがトレーニングされるのは正確ではありません。いずれにせよ、コンピュータが学習できる方法の例として、それを取ってください。遺伝的アルゴリズムはまた非常に楽しい内容を作ります。
最近まで、機械学習が適用されてきた最も重要な分野は、コンピュータビジョンであり、AIモデルは画像内のオブジェクトを認識できます。
ロボットと自動運転車はコンピュータビジョンを使用してナビゲートします。あなたの電話のカメラはそれを使用して、あなたが撮影しているものに基づいて設定を調整します。そして工場は生産ラインを離れる前に障害を検出できます。
それはまた現代医学で診断の援助として重要な役割を果たしています。例えば、それはあなたの爪の写真から自己免疫疾患を検出するのに役立ちます。
ニューラルネットワークはあなたのマイクロフォンのノイズを減らしてビデオ通話がより良く聞こえるようにすることから、より良いロケットエンジンを作成するための産業デザインに支援まで、至る所で使用されています。
サイバーセキュリティにおけるニューラルネットワーク
著者:クリスタル・モリン、シニアサイバーセキュリティストラテジスト
先ほども述べたように、最新のスパムフィルタとプロファイラーはニューラルネットワークを使用しています。
ニューラルネットワークの使用により、プロファイラーは複数のソースからデータを処理できます。例えば、銀行はあなたのすべてのアクティビティをニューラルネットワークに供給して疑わしいアクティビティにフラグを立てることがよくあります。
しかし、サイバーセキュリティのための正確な単一目的のニューラルネットワークを構築することは困難です。テクノロジーはあまりにも頻繁に変わり、モデルをデバッグするのはほぼ不可能です。
これらのモデルのセキュリティ用途はほぼコンピュータビジョンと生体認証(指紋センサー、顔認識、監視カメラなど)に限定されているのはそのためです。
ニューラルネットワークで生まれた新しいサイバーセキュリティ分野は、敵対的トレーニングです。それは、ダークAI攻撃(迂回やデータ中毒など)に関する研究です。2017年、セキュリティ研究者が交通信号を修正することで自動運転車を加速させたときに、これらの種類の攻撃が人気になりました。
生成型AI:LLMと拡散
著者:マヌエル・ボイラ、シニアソリューションズアーキテクト
しかし、現在のAIハイプは上記と何の関係もありません。今日、誰もが人工知能について知っていることは、生成型AI:テキスト(大規模言語モデル)または画像(拡散モデル)などのコンテンツを生成できるアルゴリズムです。
これらはまだ核心ではニューラルネットワークであり、いくつかの追加された機能です。
大規模言語モデルを作成する
簡素化するために、大規模言語モデル(LLM)は、テキストの次の単語を予測するためにトレーニングされたニューラルネットワークとして始まります。あなたの電話のキーボードの予測テキストのようなものです。
それは可能な限り多くの書かれたテキストに基づいてトレーニングされ、そのテキストはAIが言語と正式な表現と技術的な表現の違いを理解できるようにいくつかのコンテキストでタグ付けされています。
この段階では、AIは既存のテキストを再現できた場合、肯定的にスコアリングされます。
しかし、「予測テキストのみで段落を書く」実験から学んだように、これはAIが無意味をのみ生成することにつながります。
2回目のトレーニングラウンドでは、モデルを改善します。
そのために、別のLLMを使用して生成されたテキストをスコアリングし、それが私たちのガードレールと偏見に合致していることを確認します。この段階でのエラーは、スコアリング関数のエラーが原因でGPT-2のバージョンがみだらになるなど、驚くべき結果をもたらす可能性があります。
トレーニングが適切に行われた場合、大規模言語モデルを取得します。
ChatGPT、Copilot、GeminiなどはすべてLLMであり、予測テキストよりもわずかに賢い統計的テキストモデルです。そのため、彼らは文法を修正することやテキストを言い換えることに優れています。彼らは見事にプログラミングも得意です。結局のところ、プログラミング言語は有限の語彙上の文法規則によって駆動されています。
しかし、彼らは数学をすることやフェイクニュースを識別するなど、ロジックと推論に関連する何かに苦労しています。幸い、人間の推論も経験と感情に根ざしているため、言語だけでは十分ではありません。
拡散による画像生成
画像の生成は少し異なります。
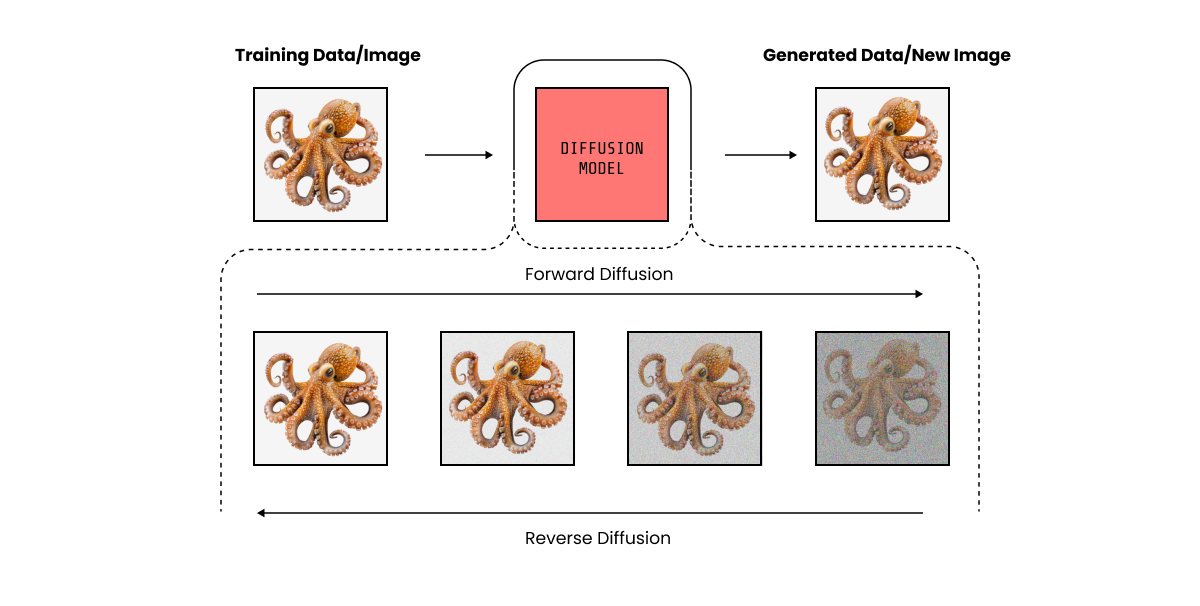
拡散モデルは、ノイズが増加するレベルでトレーニングされているコンピュータビジョンモデルの進化です。
画像を生成するために、ノイズパターンから始めます。その後、モデルは、私たちが要求したものにより見えるようにピクセルを移動します。このプロセスは、画像にノイズがなくなるまで何度も繰り返されます。
拡散モデルは構成に優れており、コンセプトアートを作成する際のブレーンストーミングに理想的です。
しかし、彼らはただの「ピクセルシェーカー」です。LLMと同様に、彼らは経験と感情を持たないため、彼らが作成する画像はしばしば不気味に見え、生命がなく、またはすべて同じに見えます。
拡散モデルはビデオにも苦労しており、オブジェクトの永続性を維持し、物理法則を理解し、時間の経過とともに一貫性を保つことが困難です。最初のモデルは、不気味な動きを隠すことによってスローモーション動画を制作しようとしました。彼らは今はいいです。トレーニングデータがモーションベクトルのような時間的メタ情報でタグ付けされているのは、トレーニングデータです。時間的一貫性はまだ問題です。10秒以上のビデオを作成できるツールはあまりありません。その時点で物事がドクター・ストレンジの映画のように見え始めるため。
サイバーセキュリティにおけるジェンAI
著者:ミゲル・ヘルナンデス、シニアスレットリサーチエンジニア
LLMはセキュリティを民主化しました。
数年前は、セキュリティアラートの重大度を理解するためにセキュリティ専門家である必要があり、インターネットで解決策を調査した後、それを実装する必要がありました。
今では、チャットボットがあなたをガイドします。まず、インフラストラクチャのコンテキストを調べて、影響を受けたリソースをあなたに提示し、その後、軽減手順を収集し、それらの実装を支援します。これは、DevOpsエンジニアもセキュリティツールを効果的に使用でき、セキュリティエンジニアは、より複雑なタスクに焦点を当てるための追加の時間を持つことができることを意味します。
これは両方の方法で機能します。セキュリティエンジニアはLLMを使用してアラートがアプリケーションのソースコードのどこに由来するかを調査し、開発チームのためのより詳細な問題を作成できます。ChatGPTとGitHub MCPサーバーを使用したセキュリティ問題の調査でこの例を見ました。
一方、サイバーセキュリティにおけるジェンAIはサイバー犯罪者にも簡単にしました。私たちの脅威研究チームは最近、脅威アクターが大規模言語モデルを操作全体を通じて活用して、クラウドサービスの発見を自動化し、悪意のあるコードを生成し、リアルタイムで決定を下すという指標を持つ攻撃を検出しました。AI支援クラウド侵入は8分で管理者アクセスを達成します。
これらの新しい脅威はより予測不可能であり、これはランタイムセキュリティの重要性を安全網として高めます。
ハイプ(と論争)は何についてですか?
AI(LLMを含む)は数十年間存在してきました。では、なぜ今のハイプはすべてありますか?
ゲームを変えたのは、コンピューティングパワーの増加です。
数年前は、モデルは特定のタスクを実行するために制限されていました。モデルはギガバイトのメモリにスケーリングでき、LLMはさまざまな問題を解決できます。1997年にディープブルーがカスパロフに勝ったときのように、別の目覚めの呼び出しを得ており、科学小説が今実現しているかもしれないと考えています。
しかし、AIはまだいくつかの本質的な課題を解決していません。それは懸念を引き起こしています。AIが人間を完全に置き換えることができない重要なエッジケースがまだあり、AIコンピューティングはリソース集約的であり、AIソフトウェアがどのように開発されるかについての倫理的な質問があります。
業界がAIハイプを追求する際に、懐疑的な心を保ち、変革的なユースケースをそれが認知負担を軽減しないものから分離する必要があります。
次は何ですか?
著者:マーラ・ロスナー、コンテンツマーケティングマネージャー。
では、次に何が起こるでしょうか?
私たちは、誰もがこの新しいテクノロジーの制限をテストしているステージにいます。何人かの人々がAIのためのゲーム変更アプリケーションを提案しているが、ほとんどのユースケースは依然として奇抜です。
現在のところ、AIはコーディングやセキュリティツールなど、いくつかのテクノロジーを民主化しました。しかし、彼らはそれらをガイドするために実際の経験を持つ人間を必要とします。
LLMがチェックされていない場合、彼らはただノイズを作成します。オープンソースコマンドラインツールであるcurlの場合、事態はそのような外的出来事に手がつけられなかったため、バグ報奨金の報酬を中止し、提出プロセスを微調整しました。実際の経験はまだ必要です。
そして、ビブコーディングは誰もが成功したプロジェクトを作成できるようになっている一方で、明白なスケーラビリティとセキュリティの問題を修正する実際のソフトウェアエンジニアの需要も作成しました。
同時に、AIはまだ進化しています。
私たちはAIチャットボットがエージェントのようにますます振る舞うのを見ており、これはエージェンティックAIと呼ばれます。このパラダイムでは、AIMCPサーバーを使用してツール間でコンテキストを共有し、情報を相関させ、複雑なタスクを実行するために他のAIと協力しています。
LLMはもう見事に速く見えていませんが、より多くの情報を管理でき、行動を起こすことができます。これは新しい自動化の時代につながっており、経験豊富な人間がこれまで以上に重要です。
AIはまだワークロードに関する詳細をお読みください。
結論
生成型AIはブロック上の新しい子どもであり、みんなの注意を集めています。しかし、古い学校のAIはまだスパムフィルター、生体認証、プロファイリング、コンピュータビジョンに住んでいます。
ジェンAIは多くのテクノロジーを民主化しましたが、人間はまだ必要です。
これが、将来的により手術的なアプローチをジェンAIで見るのは、人間の置換ではなく、微妙なアシスタントのようなものです。
この記事が気に入ったら、シリーズの他のものをチェックしてください:
翻訳元: https://webflow.sysdig.com/blog/masterclass-ai-is-more-than-chatgpt-and-llms


