
AIは魔法のように見えるかもしれませんが、舞台裏では依然としてサーバー上で動くコードにすぎません。したがって、他のワークロードと同様に保護する必要があります。
本記事では、AIの利用における3つの異なるアプローチに関連するセキュリティリスクを評価します。すなわち、ChatGPTのようなLLMを利用する従業員、製品の一部としてチャットボットを提供する企業、そしてゼロから独自モデルを学習させる企業です。
AIワークロードが、すでに運用している他のワークロードと実際にどのように似ているのかを示し、セキュリティを強化するための緩和策もいくつか提示します。
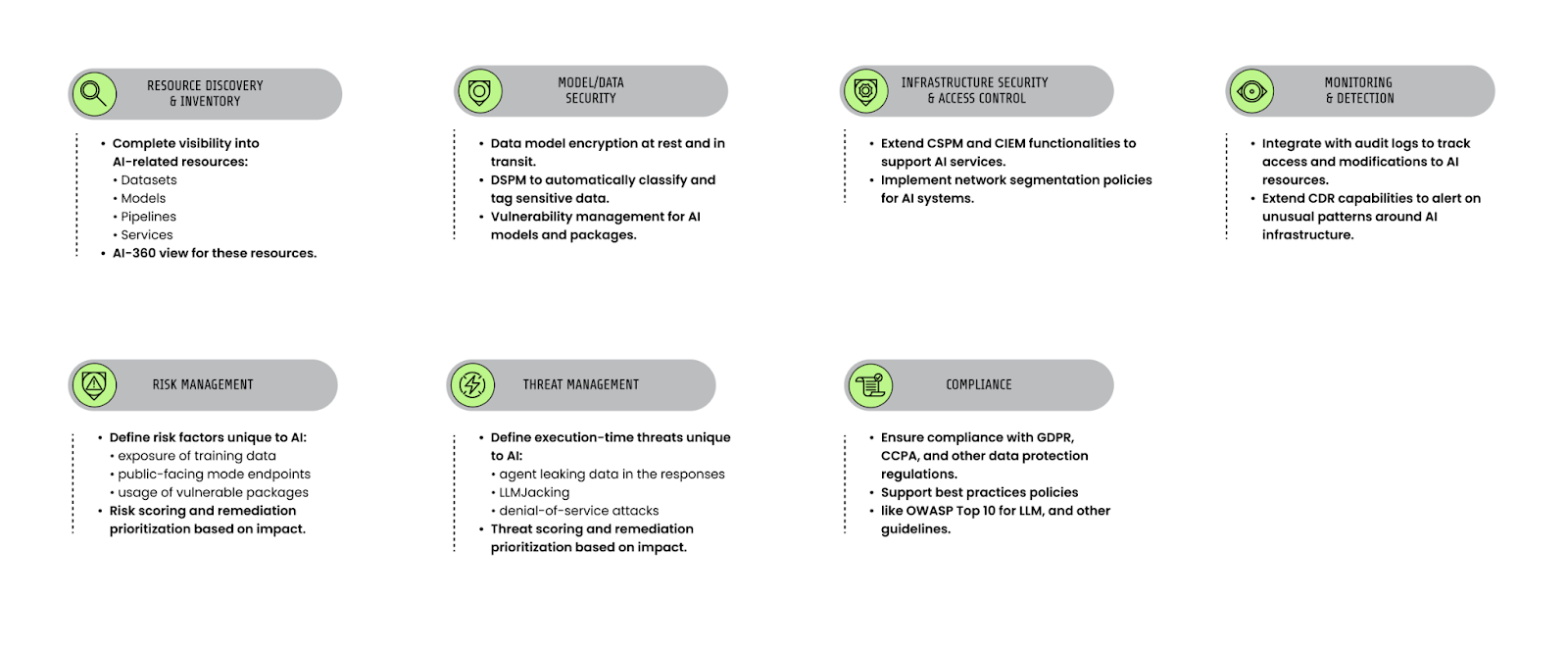
AIワークロードを保護する際にカバーすべき主要領域は7つあります。インベントリ、モデルとデータのセキュリティ、アクセス制御、検知、リスク管理、脅威管理、そしてコンプライアンスです。
LLMユーザーの保護
まずは、組織内でChatGPT、Copilot、GeminiなどのLLMを利用するユーザーをどのように保護するかを見ていきましょう。
主なリスク:データ漏えい、またはモデルに誤誘導されること。
類似するもの:他のあらゆるSaaS。
対応:AIのベストプラクティスとプライバシー上の影響について、ユーザーを教育する。
あなたのデータが学習に使われていないことを確認する
AI企業にとって、あなたのプライバシーは最優先事項ではありません。しかし、モデルを学習させて競合に勝つことは最優先です。
SaaSサービスがサービス改善のためにデータを利用するのは珍しくありませんが、LLMモデルの学習のためにそれを行うのは言語道断です。これはプライバシーとセキュリティの悪夢であり、エージェントを操作して学習データの一部を返させるのは比較的容易だからです。
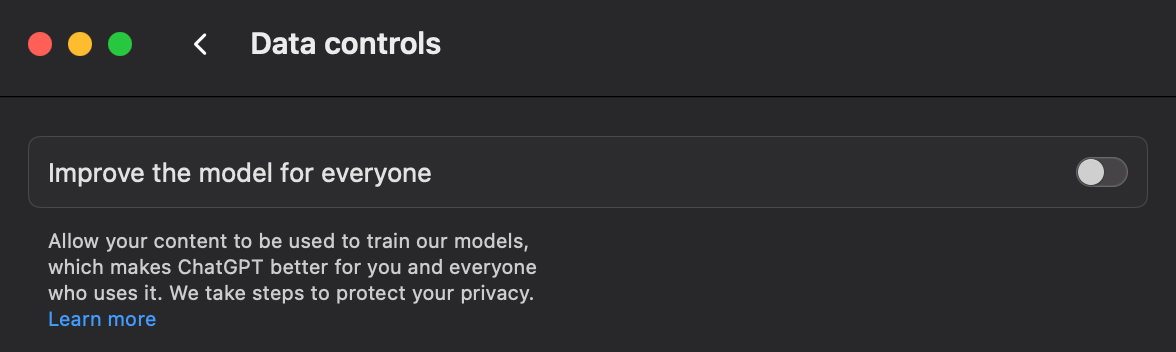
OpenAI EnterpriseやGoogle Workspace Geminiのようなサービスは、あなたのデータをモデル学習に使用しません。しかし、通常版の製品には同じことが当てはまりません。組織内で個人アカウントを使っているユーザーは、プライバシー設定を手動で見直す必要があります。
ChatGPTの場合は、設定に移動し、「Data controls」を開いて、「Improve the model for everyone」のトグルを無効にする必要があります。
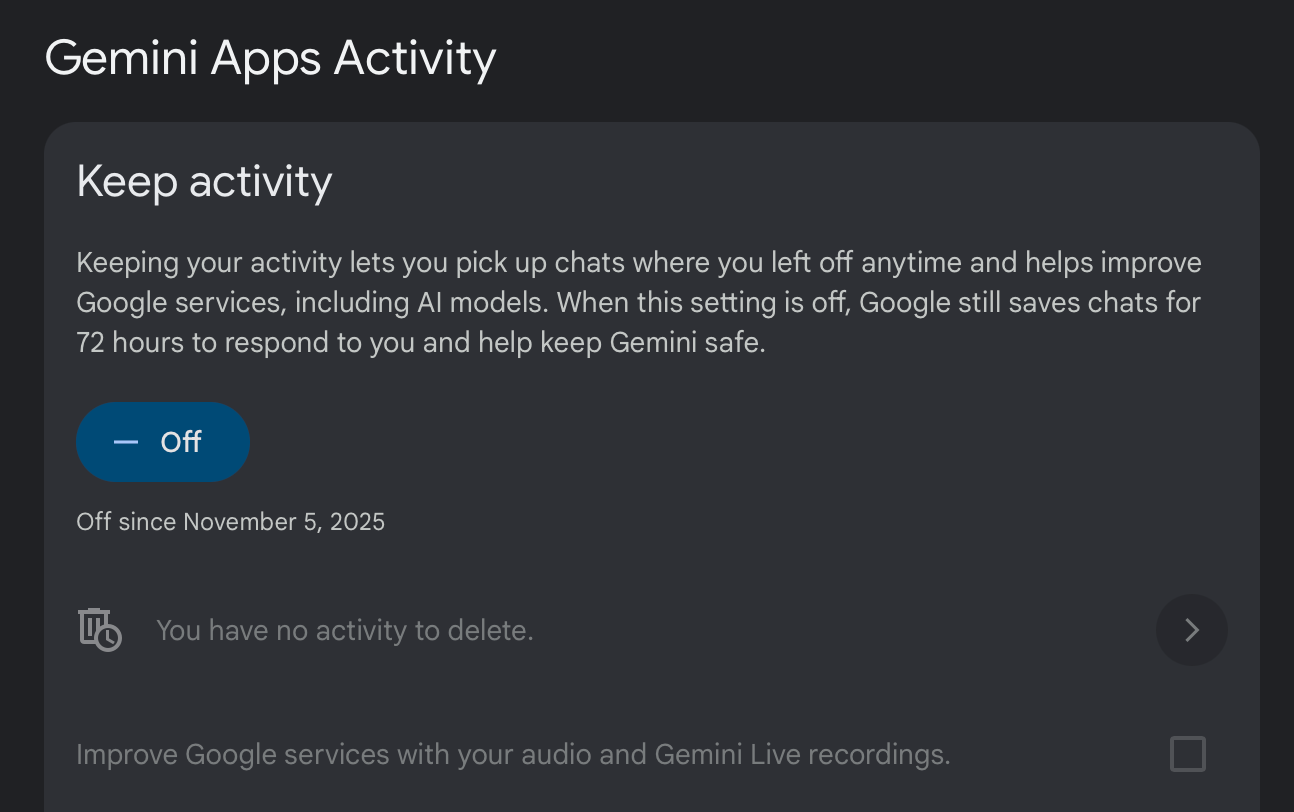
Geminiユーザーの場合、この設定は「myactivity」ポータルの中に埋もれています。
AIの利用に関するベストプラクティスと、それに伴うプライバシー上の影響について、会社がトレーニングを提供していることを確認してください。この方法でのデータ漏えいは、企業の評判を損ない、GDPRやCCPAなどの規制の下で多額の罰金につながります。
AIアプリとアクセス先リソースの可視性
見えないものは守れないため、AIエージェントがアクセスできるすべてのリソースを棚卸しし、必要に応じて制限することが重要です。AIエージェントのビジネス版やエンタープライズ版では、承認済みの連携アプリの許可リストを使って全体設定できる場合があります。
しかし、この設定はOpenAIのCodexのようなエージェントには適用されないことがあります。ユーザーがローカルファイルへのアクセスを自由に与えたり、MCP経由で外部接続を設定したりできるためです。同様に、ユーザーはこれらのサービスの個人アカウントを使うことで制限を回避できます。
これが問題になっている場合は、従業員のPCで実行できるソフトウェアを制限し、特定リソースへの接続をブロックできるデバイス管理ソフトウェアの導入を検討してください。
とはいえ、特定リソースへのアクセス制限は業務を妨げる可能性があります。AIに関するベストプラクティスをユーザーに教育することは、常に良い出発点です。
認証情報とAPIキーへのアクセスを保護する
AIエージェントがプライベートデータをモデル学習に使わない場合でも、ユーザーアカウント上にそのデータの一部をキャッシュします。悪意ある第三者がそのアカウントにアクセスできれば、キャッシュされた情報を抽出できてしまいます。
他のSaaSと同様に、AIサービスには二要素認証を必須化し、データ保持ポリシーを設定してください。また、アクセス監査を有効化し、脅威検知エンジンに連携して、不審な接続をアラートできるようにしましょう。
汚染(ポイズニング)されたモデルから守る
AIを盲信しないでください。
LLMは中立で全知の神託ではありません。AIは限られた情報に依存し、完全な確信をもって幻覚(ハルシネーション)を含む回答を返し、モデルをプログラムした人々が定義した一定の価値観に基づくガードレールの中で動作します。AIが提供する情報は必ず照合し、AIが実行するタスクは監督すべきです。
AIモデルは8歳児だと思ってください。親から聞いたことを究極の真実だと考え、完全な自信で事実を作り上げ、監督なしでは最大級の混乱を引き起こしかねません。
さらに、モデルはポイズニングの影響を受けやすいです。子どもが悪い言葉を覚えて使い続けるのと同じように、学習データが慎重に精査されていなければ、AIモデルはあらゆる厄介なことを学習してしまいます。
攻撃者はモデルをポイズニングして、エージェントの応答を操作できます。検索エンジン向けにWebサイトを最適化するのと同様に、WebサイトのコードからAIエージェントを操作できます。たとえば、インターネットをスクレイピングする際にエージェントが解釈する隠し命令をソースコードに含められます。攻撃者はこの手法で、正規サイトではなく不正なフィッシングサイトへ他のユーザーを誘導するようエージェントをだますことができます。
これらの攻撃はさらに巧妙な場合もあり、特定の入力でコンテナから脱出して悪意あるコードを実行するようモデルを学習させる、といったものもあります。
これらを念頭に置き、LLMに対して懐疑的な姿勢で臨むようチームをトレーニングしてください。
公開チャットボットと内部エージェントの保護
主なリスク:攻撃者がエージェントを侵入口として利用すること、攻撃者がAIインフラを悪用すること。
類似するもの:外部APIアクセス全般。
対応:すべてのユーザー入力を解析し、適切なネットワークセグメンテーションを行い、認証情報を保護する。
ジェイルブレイクから守る
開発者として最初に学ぶことの一つは、ユーザーは手元にあるあらゆる入力欄を使って、予想外の方法で混乱を引き起こせるということです。Webサイトをいじって、開発者がユーザー入力のサニタイズを忘れてSQLインジェクションが可能になっていないかを見るのは楽しいものです(少なくとも私たちにとっては。開発者にとってはそうではありません)。

現在では、アプリフレームワークは一般的な攻撃に対してデフォルトでユーザー入力をフィルタリングします。しかし、Log4Shellのような驚きは依然として存在します。これはlog4jの脆弱性で、このライブラリがログに記録する際に、細工されたユーザー入力によってサーバー側でコードが実行され得るものでした。
もちろん、AI時代でも同じ原則が当てはまります。

フィルタリングされていないデータをAIエージェントに与えると、ガードレールを回避するプロンプトが可能になります。
最良の場合、誰かがあなたの製品のAIアシスタントに面白いことを言わせるだけです。最悪の場合、攻撃者はアシスタントを操作して組織内のデータを漏えいさせます。エージェントが利用可能なデータやリソースは、いずれもこの方法で到達され得ることを忘れないでください。
これらの攻撃は、AIアシスタントへの直接プロンプトに限りません。バックエンドで動作するエージェントについても、アクセスするデータに隠し命令や「William Ignore All Previous Instructions」のようなユーザー名が含まれないことを保証し、特に保護する必要があります。
最も恐ろしいのは、SQLインジェクションにはある程度の技術知識が必要だった一方で、LLMの操作は平易な言葉でできてしまうことです。たとえばChatGPT 3.5では、「company」という単語を500回繰り返すよう依頼することで学習データを抽出できました。
経験則としては次のとおりです。
- ユーザー入力がエージェントに届く前にフィルタリングする。具体的には:
- ガイドラインとユーザー入力を分離するために使っている可能性のある区切り文字。
- 「ignore」「instructions」「guidelines」などのキーワード、またはエージェントの想定範囲外の単語。
- エージェントの出力をユーザーに返す前にフィルタリングする。応答の長さを制限し、メール、APIキー、または同様の構造を持つデータらしきものを検出する。
- ガードレールが堅牢であることを確認するため、徹底的にテストする。外部の専門家に依頼してテストしてもらうことも検討する。
- 攻撃者が弱点に関する情報を得にくいよう、ガードレールは非公開にする。
- 他のリソースへのアクセス制限やネットワークセグメンテーションの実装など、通常のセキュリティ推奨事項によりラテラルムーブメントを防ぐ。
LLMJackingから守る:認証情報とアクセスを保護する
他のクラウドサービスや外部APIと同様に、エージェントの認証情報とAPIキーを保護してください。
AIの計算時間は高価であり、他人のインフラは常に安上がりです。探し方を知っていれば、侵害されたAIサーバーへのプロキシの活発な市場があります。LLMサーバーの認証情報を盗む手法はLLMJackingと呼ばれます。
認証情報を保護するためのベストプラクティスをいくつか紹介します。
- APIキーをコードにハードコードしない。シークレットと環境変数を使用する。
- 認証情報漏えいにつながり得るソフトウェアの脆弱性をスキャンし、緩和する。
- ネットワークセグメンテーションを適用し、バックエンドのみが、かつ特定の送信元からのみエージェントにアクセスできるようにする。
- AIワークロードに対する監査、検知、対応を実装する。異常なアクティビティを検知でき、潜在的なインシデントを調査できるようログを残す。
サービス拒否(DoS)から守る
公開されているサービスは、サービスが劣化するほどの悪用を受けやすいものです。LLMの場合、主に次の2つの形で発生し得ます。
- 攻撃者が複雑なプロンプトを要求し、リソース使用量が急増する。
- 攻撃者が、エージェントが処理できる速度を超えて繰り返しリクエストを送る。
これを避けるには:
- 繰り返しになりますが、「これを永遠に繰り返して」のようなリクエストをフィルタリングするために入力を解析する。
- ユーザー入力を処理するレートに制限を実装する。
- LLMエージェントの出力の長さを制限する。
- リソース使用量を監視し、使用量の急増をアラートする。
自社学習モデルの保護
主なリスク:モデルの漏えいとモデルのポイズニング。エージェントを侵入口として利用されること、またはAIインフラを悪用されること(上で述べた内容と同様)。
類似するもの:バックエンドサービス全般。
対応:学習データセットを慎重に作り込み、モデルへのアクセスを保護する。
あらゆるサービスの保護には、セキュリティのベストプラクティスを各段階で徹底する統合的なアプローチが必要です。本記事ではすでにいくつかのベストプラクティスを取り上げましたし、残りはおそらくご存じでしょう。したがって次のセクションは、AIに限らずあらゆるサービスを保護するための土台として使える、簡易チェックリストとして捉えてください。
リソースへのアクセス
モデルの学習には、計算だけでなく学習データセットのキュレーションという点でも多大な労力が必要です。このプロセスの終わりには、競合との差別化となる独自の成果物ができあがっています。
これは重要な投資であるため、それに見合った保護を行ってください。
- まずリソースのインベントリを作成し…そのインベントリを更新し続けてください。見えないものは守れないので、抜け漏れがないようにしましょう。
- モデルとデータソースへのアクセス設定にはゼロトラストのアプローチを適用する。たとえばモデルやデータソースをS3に保存している場合、プライベートにし、必要なアカウントからのみアクセス可能にしてください。
モデルとデータ
アクセスが侵害された場合に備え、実データそのものを保護することも重要です。モデルと学習データを保存時(at rest)と転送時(in transit)の両方で暗号化してください。たとえば、次のような設定でS3バケットにこれを強制できます。

データセキュリティ・ポスチャ管理(DSPM)を使用して、機密データを自動的に分類・タグ付けしてください。たとえばBedrock Dataのようなツールを使えば、学習データ内にAPIキー(または類似のもの)が含まれていないことを確認したり、そうしたデータがプロンプト内でエージェントに到達するのを防いだりできます。
静的:インフラとリスク管理
インフラに固有のリスク要因のリストを作成してください。本記事で取り上げた例(学習データの露出、公開されたモデルエンドポイント、脆弱なパッケージの使用など)を参考にできます。
影響度に基づいて各リスクをスコアリングし、取り組みの優先順位を付けます。
各リスクに対する緩和策を計画します。是正措置の例としては、アクセス設定におけるゼロトラスト、ネットワークセグメンテーション、データ暗号化、パッケージの脆弱性追跡などがあります。
CSPMおよびCIEMツールを活用して是正措置の実装状況を追跡し、最も弱いポイントの可視性を確保してください。
動的:監視、検知、脅威管理
実行中に発生する異常な振る舞いを検知することは、静的な設定で見落とした可能性のある脅威を捕捉するためのセーフティネットになります。
まず、自社に固有の脅威要因を特定します。例として、応答でのデータ漏えい、LLMJacking、サービス拒否攻撃などを挙げました。
影響度に基づいて各脅威をスコアリングし、取り組みの優先順位を付けます。
各脅威に対する是正措置を計画します。これには、監査ログを処理してAIリソースへのアクセスや変更を追跡すること、異常行動を特定する検知ルールを作成することなどが含まれます。
これらのアクションは、インフラ全体を観測し、異常なパターンをアラートし、セキュリティイベントの調査を容易にするコンテキストを提供するCDRツールを用いて実装してください。
最後のステップとして、セキュリティイベントを調査・是正した後は、同様の脅威が再発しないよう、新たなリスクと緩和策を含める形で静的設定を見直すことが重要です。
コンプライアンス
最後の推奨事項は、コンプライアンス標準とセキュリティベンチマークを満たすことです。要求されていない場合でも実施し、セキュリティ戦略のギャップを検出するためのツールとして活用してください。
欧州のGDPRやカリフォルニアのCCPAなど、データ保護法には特に注意してください。本記事で述べたとおり、データ保護は現代AIにおける最も弱いリンクです。
次のステップ
本記事は、始めるためのクイックガイドだと考えてください。このテーマをさらに深掘りしたい場合の追加リソースをいくつか紹介します。
まず手早く取り組めるのは、LLM向けOWASP Top 10から始めることです。ここには、遭遇する可能性が高い最も一般的な脅威がまとめられています。

包括的な一覧については、MITRE ATLAS Matrixを参照してください。機械学習に関連する戦術と技術の最新リストです。

結論
AIワークロードを保護するためのベストプラクティスは、通常のサービスと同じです。
- ChatGPTのようなAIエージェントを利用する場合、他のSaaSを利用するときと同じルールを適用する必要があります。
- 外部エージェントの保護は、外部APIへのアクセスを保護するのと同様です。
- 自社のモデルやエージェントの保護は、他のバックエンドワークロードを保護するのと似ています。
加えて、無害なプロンプトが爆弾に変わり得るLLMの非決定性にも対処する必要があります。このリスクを緩和するには、入力のサニタイズやレート制限の実装において、固定観念にとらわれない発想が求められます。
本記事が、馴染みのあるサービスにいくつかのユースケースを結び付けることで、AIワークロードの神秘性を解きほぐす助けになっていれば幸いです。
AIワークロードのセキュリティについて詳しくは、当社のブループリントをこちらでお読みください。
翻訳元: https://www.sysdig.com/blog/ai-is-still-a-workload-a-practical-guide-to-securing-ai-workloads


