
はじめに
クラウドにおけるセキュリティ侵害は高い頻度で発生しており、事前の計画が不可欠です。しかし、すべての脅威を防げるわけではありません。
強固な予防的セキュリティ態勢があればインシデントとは無縁だと考える人も多いですが、実際に起きたときに不意を突かれがちです。侵害は不可避であるという前提で運用し、それに備えるほうが賢明です。クラウド攻撃がより高速かつ高度になり、脅威環境の予測が難しくなるにつれて、セキュリティリーダーは先手を打つために「侵害前提(assume breach)」の考え方を受け入れる必要があります。
AWS環境におけるインシデント対応は、クラウドベースのアプリケーションとインフラのセキュリティ、可用性、そして全体的な健全性を維持するうえで極めて重要です。動的なクラウドインフラの世界では、セキュリティインシデントからの復旧—そしてそれを引き起こした脅威アクターの追跡—には、明確に定義され、訓練されたインシデント対応計画が必要です。堅牢なインシデント対応能力がなければ、組織は多大な金銭的損失、評判の毀損、法的影響、機密データの漏えいといったリスクを負います。
幸い、インシデント対応を支援するオープンソースツールは多種多様に存在します。本記事では、それらをどのように活用できるかを示し、取り組みを支援する新しい公開MCPサーバーも紹介します。
AWS責任共有モデル
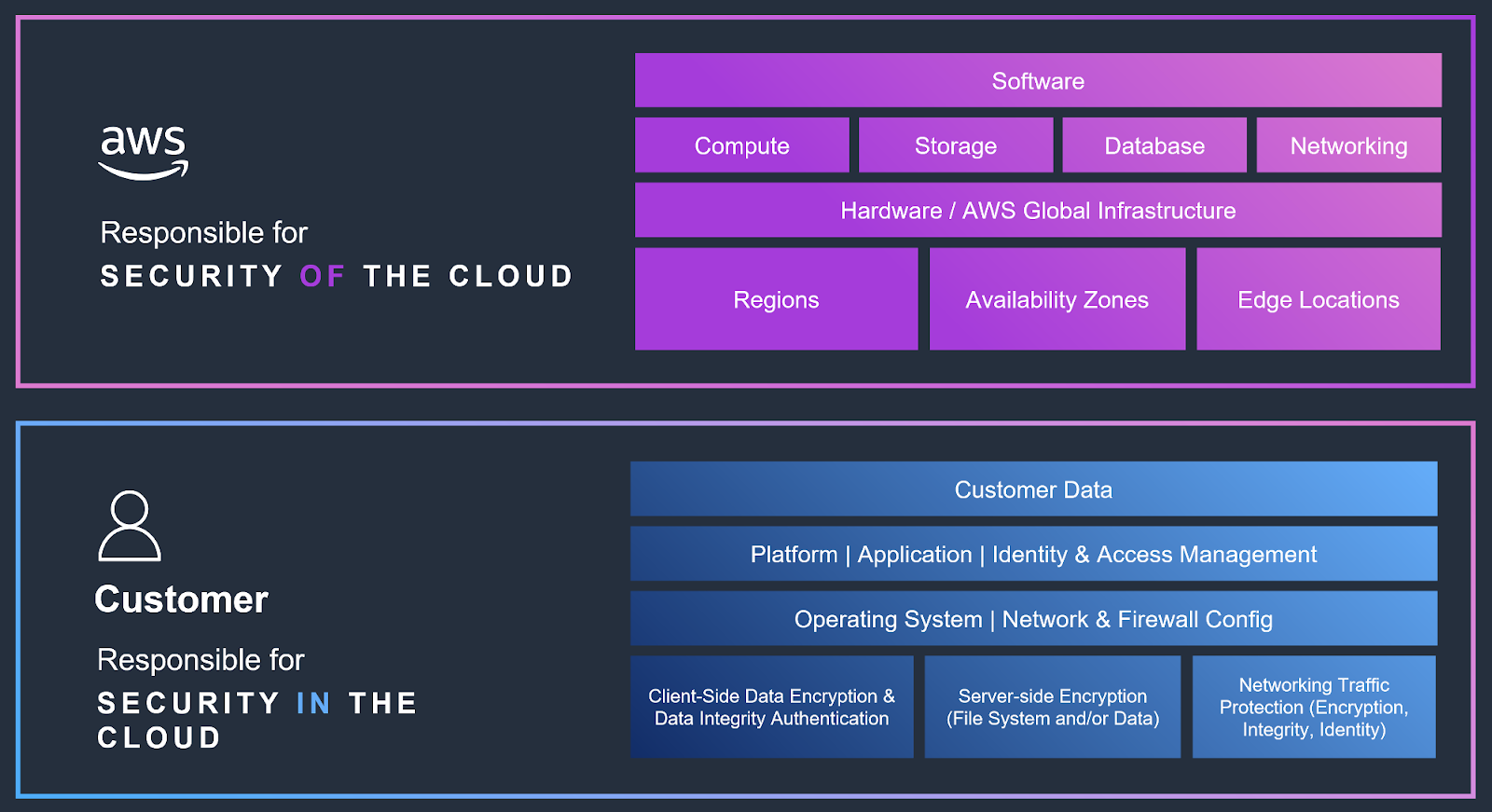
責任共有モデルは、AWS環境におけるインシデント対応の基盤です。AWSと顧客の間でセキュリティ責任の分担を明確に定義し、インシデントの取り扱いと管理の方法に影響します。AWSはクラウドそのもののセキュリティ(インフラおよび基盤サービス)に責任を負います。顧客はクラウド内のセキュリティ(データ、アプリケーション、OS、ネットワークトラフィックなど)に責任を負います。
インシデント対応において、この区別は侵害のどの側面を誰が調査・是正するかを定めます。AWSはインフラの脆弱性やサービス障害に関する問題に対処し、顧客は侵害されたデータ、設定ミス、アプリケーションの悪用に関わる欠陥を管理しなければなりません。このモデルにより、インシデント対応中の明確性と協力が確保され、AWSと顧客がそれぞれ異なるが補完的な役割を担って環境全体のセキュリティを守ります。
AWS組織の構造
AWSアカウントの組織構造として、セキュリティ用とフォレンジック用の組織単位(OU)をそれぞれ1つ含める構成をユーザーが設定することが推奨されています。
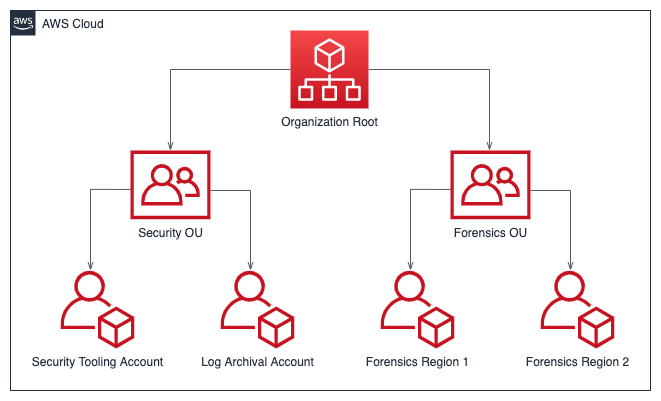
AWS組織でセキュリティ用OUとフォレンジック用OUを分けることには、インシデント対応においていくつかの利点があります。
- 職務分離:セキュリティOUは予防的なセキュリティ対策やツールに集中し、フォレンジックOUは事後の調査と分析に集中できます。
- アクセス制御:OUごとに異なる権限セットを適用でき、機微なフォレンジックツールやデータへのアクセスを制限できます。これにより、フォレンジック証拠の完全性を維持しやすくなります。
- リソース分離:フォレンジック活動を別環境で実施でき、本番システムを汚染するリスクを低減できます。
- 機密性:この組織モデルは調査の機密性維持に役立ちます。
- コスト追跡:OUを分けることで、セキュリティ運用とフォレンジック活動に関連するコストの追跡・配賦が容易になります。
- スケーラビリティ:フォレンジックOUは、他のセキュリティリソースに影響を与えず、調査ニーズに応じて独立にスケールできます。
- 監査証跡:フォレンジックOUでの操作は、通常のセキュリティ運用とは別に追跡・監査しやすくなります。
- 影響範囲(blast radius)の縮小:あるOUで侵害が発生しても、他のOUへの影響を最小化できます。
- サービスクォータ枯渇の回避:脅威アクターがあるサービスのクォータ上限に達した場合でも、OUを分離しておけば、調査のためのリソース(例:EC2インスタンス)作成が妨げられません。
インシデント対応フェーズとAWSサービス
包括的なAWSインシデント対応計画は、以下に示すように複数のフェーズを包含すべきです。
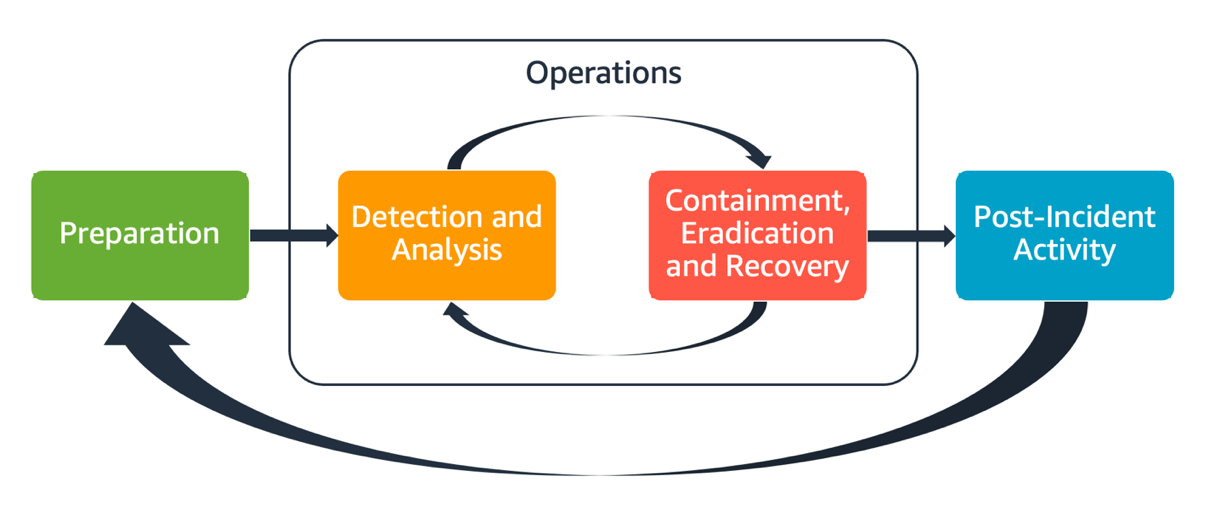
この計画では、これらのフェーズで複数のAWSサービスを用いて、徹底した脅威調査と対応を実施します。
- AWS CloudTrail:APIアクティビティのログ取得
- 準備:S3など特定のAWSサービスについて、データイベントのログを適切に有効化することが重要です。詳細は本記事の後半で説明します。
- 検知と分析:CloudTrailはAWSにおける主要なログソースです。CloudTrailログは、検知ルールを活用して不審なAPIアクティビティをユーザーに通知するサードパーティソフトウェアへ転送できます。EventBridgeも、CloudTrailログのパターンに基づいて他サービス(Lambda関数やSNSトピックなど)のリソースをトリガーするために利用できます。
- Amazon Athena:ログのクエリとデータ分析
- 準備:パーティション化したAthenaテーブルを用意し、調査時に役立つクエリテンプレートを準備しておくと有用です。
- 検知と分析:AthenaはSQLクエリを用いて、さまざまなログ種別の詳細分析に利用できます。
- Amazon CloudWatch:監視とアラート
- 準備:AWSサービスがCloudWatchへログを送信するよう設定し、不審な挙動の可能性に対するアラームを設定します。CloudWatchはログストリームとしてイベントを保存するロググループを作成します。機微なロググループに対しては異常検知器(anomaly detector)の作成も推奨されます。異常検知は機械学習アルゴリズムを用いてメトリクスの期待値に基づくモデルを学習し、逸脱した挙動に対してアラートを出す可能性があります。
- 検知と分析:CloudWatchログには、CloudTrailログと比べてイベントに関するはるかに多くの情報が含まれる場合があります。そのため、CloudWatchはインシデント対応の分析フェーズにおいて重要なサービスです。
- Amazon GuardDuty:脅威の検知と調査
- 準備:保護したいリージョンでGuardDutyを有効化し、その脅威検知機能を活用します。EC2インスタンスやS3バケット向けのマルウェア保護など、追加の保護オプションも有効化できます。また、複数イベントの連続における不審なパターンを特定する拡張脅威検知(Extended Threat Detection)もあります。
- 検知と分析:GuardDutyダッシュボードには検出結果(findings)の一覧が表示され、重大度、検出種別、影響リソースなどでグルーピングできます。1つの検出結果を開くと潜在的脅威に関する多くの詳細が確認でき、さらに調査を進められます。
- AWS Config:リソース設定管理と変更追跡
- 準備:Configはセキュリティインシデント調査中に価値ある資産となります。そのため、このフェーズでリソースのあるすべてのリージョンで有効化し、組織要件に沿ってリソースを適切に設定しておくべきです。
- 検知と分析:このサービスはAWSリソース設定を継続的に監視・記録し、時間経過に伴う変更を追跡できます。 インフラの履歴ビューは、セキュリティイベント分析時に重要な文脈を提供します。このフェーズでは、Configを活用して設定変更の特定、コンプライアンス状態の評価、過去状態の再構築、不正変更が行われた場合の詳細な監査証跡の提供が可能です。
- AWS Security Hub:セキュリティ態勢管理
- 準備:Security Hubは、セキュリティのベストプラクティスと標準準拠のための中核ハブとして機能します。さまざまなAWSサービスやサードパーティツールからの検出結果を集約し、ベースラインとなるセキュリティ態勢を確立できます。このフェーズでSecurity Hubとその統合を有効化することで、効率的な検知と分析の基盤を整えられます。
- 検知と分析:AWS Security Hubは、Amazon GuardDuty、AWS Config、AWS IAM Access Analyzerなど複数のAWSサービスからのセキュリティ検出結果を集約し、優先順位付けします。これにより、セキュリティとコンプライアンス状況を統合的に把握でき、潜在的インシデントの迅速な特定が可能になります。また、Security Hubは実行可能な洞察と是正ガイダンスを提供し、セキュリティ問題の調査と対応を効果的に支援します。
- IAM:アクセス制御とユーザーID管理
- 準備:インシデント対応手順のための適切なIDおよびアクセス管理(IAM)ロールと権限を確立することが、このフェーズでは不可欠です。これらのロールは、アカウント横断でサービスやリソースへアクセスするために利用されます。
- 検知と分析:IAM Access Analyzerは、リソースポリシーにおける権限変更を監視し、リスクの高いパターンに基づいて検出結果を生成します。重要リソースへの外部アクセス、内部アクセス、未使用アクセスを特定でき、危険な設定をリアルタイムで修正するのに役立ちます。
以降のステージは、影響を受けたサービスに依存します。
- 封じ込め(Containment)は、特定されたインシデントの範囲と影響を制限することを目的とする重要なステップです。セキュリティグループルール、ネットワークACL(NACL)、IAMポリシーを変更することで、EC2インスタンスやS3バケットなど影響を受けたリソースを隔離します。
- 根絶(Eradication)は、インシデントの根本原因を除去し、仕込まれたマルウェアや悪用された脆弱性を排除することに焦点を当てます。脆弱なシステムのパッチ適用、悪意あるソフトウェアの削除、侵害された認証情報の無効化、設定ミスのあるリソースの再設定などが含まれます。根絶では、攻撃者がAWS環境から完全に遮断され、境界内に(バックドアのような)アクセス手段が残っていないことを確認することが重要です。
- 復旧(Recovery)は、影響を受けたシステムやサービスを通常の運用状態へ戻すことを指します。バックアップからのデータ復元、アプリケーションコンポーネントの再デプロイ、封じ込めフェーズで実施した制限の解除などが含まれます。
- 事後分析(Post-incident analysis)は、インシデントの根本原因を特定し、インシデント対応プロセスの有効性を評価し、改善提案を策定することを目的とします。インシデントのタイムライン、実施した対応、対応上の不足点を文書化します。事後分析で得た教訓を反映することで、組織のセキュリティ態勢が強化され、AWS環境で将来のインシデントに対処する能力が向上します。
AWSでのインシデント調査
インシデント調査は常に多段階の旅であり、私たちは次の点を追跡し理解したいと考えます。
- 初期侵入の手段
- 影響を受けたすべてのリソース
- 影響を受けたすべてのID(アイデンティティ)
- 他環境への横展開(ラテラルムーブメント)の可能性
- インフラから遮断しようとする試みを生き延びるために攻撃者が用いた可能性のある永続化手法
これらのステージの成功は、インシデントに備えてAWSアカウントを準備するために講じた予防策に依存します。包括的なログ取得能力こそが、適切な調査と対応の主要要素です。
AWSインシデント対応のためのオープンソースMCPサーバー
以下の調査手順を通じて、AWS-IReveal-MCPを含む、インシデント対応向けの複数のオープンソースツールに言及します。これはSysdig Threat Research Teamが開発したMCPサーバーで、前述のAWSサービスと統合します。不審なアクティビティの分析中に支援してくれるアシスタントだと考えるとよいでしょう。また、調査で得られた発見に基づいて是正策も提案します。
AWS CloudTrail
AWSアカウントに問題があったのではないかと懸念している場合、何が起きたのかの見当をつけるために最初に確認する場所は、おそらくAWS CloudTrailでしょう。
トレイルを作成すると、デフォルトでは管理イベントのみのログが有効になり、データイベント、ネットワークアクティビティイベント、Insightsは有効になりません。これらは追加コストで有効化できます。
- データイベントは、リソースレベルで発生するデータプレーン操作です。たとえば、S3バケット内のファイルに対するアップロード、ダウンロード、削除などの操作はデータイベントです。AWSサービスごとのデータイベントの一覧はこちらです。データイベントが有効化されていないサービスがインシデントの影響を受けた場合、適切に調査するのが難しくなる可能性があります。
- ネットワークアクティビティイベントは、VPC内で実行される管理プレーンおよびデータプレーン操作の可視性を提供します。これらのイベントは特定のサービスでサポートされています。高度なイベントセレクターを設定することで、有効化するサービスを選択できます。eventName、errorCode、vpcEndpointIdの任意のイベントセレクターを指定し、特定のシナリオのみをログに記録することも可能です。たとえばVPCエンドポイントを使用している場合、VPCエンドポイントポリシー違反によりエラーVpceAccessDeniedとなったネットワークアクティビティをログに残したいことがあります。サポート対象サービスの一覧と、高度なイベントセレクター設定例はこちらです。
- Insightsは、APIコール量やエラー率に基づく異常な挙動の指標です。Insightsは、アカウントの通常の利用パターンと比べて大きな差異を強調してくれるため有用です。
メンバーアカウントごとに1本のトレイルを作るのではなく、組織トレイルを設定するのが良いプラクティスです。どのリージョンのイベントも取りこぼしたくないため、トレイルはマルチリージョンにすべきです。また、S3バケットに保存されるトレイルログはObject Lockを設定して保護してください。
CloudTrailは、LookupEvents APIを呼び出すイベント履歴(Event history)によって基本的なフィルタリングを提供します。これは不審なアクティビティを調査するための良い出発点です。次のスクリーンショットは、サンプルプロンプトを用いたAWS-IReveal-MCPの動作を示しています。

Clineで動作するMCPサーバー
以下に示すように、特定の命名パターンを持つロール、またはロールの集合によって実行された操作をたどるよう依頼することもできます。

Claude Codeで動作するMCPサーバー
ここでは敵対者エミュレーションテストを実施するためにStratus Red Teamを利用しました。LLMはそれを正しく指摘しました。

CloudTrailログを調査する際に留意すべき重要ポイントをいくつか挙げます。
- sessionCredentialFromConsoleフィールドが存在する場合、そのイベントはWebコンソールから生成されています。
- ec2RoleDeliveryフィールドが存在する場合、そのイベントはEC2インスタンスのIMDSから認証情報を取得したプリンシパルによって生成されています。値は、そのインスタンスがIMDSv1を使用していたかIMDSv2を使用していたかを示します。
- ログにinvokedBy:AWS Internal(通常はsourceIPAddress:AWS InternalおよびuserAgent:AWS Internalを伴う)が含まれる場合、そのイベントはAWSによって生成されています。これは必ずしも、そのイベントを悪意あるものとして扱うべきではないという意味ではありません。たとえば、攻撃者が侵害されたアカウントから組織内の別アカウントへSwitchRoleを行うと、invokedBy:AWS Internalを伴うAssumeRoleが発生します。
- userAgentの値は、リクエスト時に任意に設定できます。
- クロスアカウントでリソースへアクセスするリクエストでは、recipientAccountIdの値はリソース所有者のアカウントIDであり、userIdentity.accountIdはリクエストを行ったアカウントのIDです。
- vpcEndpointIdフィールドが存在する場合、そのリクエストはVPCから生成されています。この場合、sourceIPAddressはVPCのIPアドレスであり、プライベートである可能性があります。攻撃者は、VPCを使用してIPアドレスを偽装するためにここで説明されている手法を用いることがあります。
CloudTrailログは、CloudTrail LakeまたはAmazon Athenaを用いてSQLでクエリし、より粒度の細かい検索が可能です。両サービスの主な違いは次のとおりです。
- CloudTrail Lakeはイベントを不変(immutable)なデータストアに取り込みます。一方Athenaは、S3上の生のJSON(または圧縮)ログファイルを直接クエリするため、ユーザーがSQLテーブルを構築する必要があります。
- CloudTrail Lakeには2つの保持オプションがあります。1つは最大10年間データストアにイベントを保持し、もう1つは最大7年間保持します。対してAthenaは、保持にS3ライフサイクルポリシーを利用します。
- CloudTrail LakeのSQL構文はAthenaより制限があります。
- CloudTrail LakeとAthenaはいずれも、クエリでスキャンされたバイト数に対して課金されます。ただし、パーティション化によりスキャン量を劇的に削減でき、大きなコストメリットが得られます。Athenaはパーティション化を完全に制御できますが、CloudTrail Lakeはデータストア内でイベントがどのように整理されるかを内部的に管理します。
本記事の目的では、Athenaを使用します。
Amazon Athena
パーティション投影(Partition projection)は、運用オーバーヘッドを削減する優れた方法です。AWS-IReveal-MCP
実装では、ドキュメントに示されたクエリを用いて、指定日以降の単一AWSリージョンのCloudTrailログに対してパーティション投影を使用するテーブルを作成します。これで、Athenaを使って不審なアクティビティの調査を始める準備が整いました。クエリの効果的なテンプレートの1つは次のとおりです。
WITH flat_logs AS (
SELECT
eventTime,
eventName,
userIdentity.principalId,
userIdentity.arn,
userIdentity.userName,
userIdentity.sessionContext.sessionIssuer.userName as sessionUserName,
sourceIPAddress,
eventSource,
json_extract_scalar(requestParameters, '$.bucketName') as bucketName,
json_extract_scalar(requestParameters, '$.key') as object
FROM <TABLE_NAME>
)
SELECT *
FROM flat_logs
WHERE date(from_iso8601_timestamp(eventTime)) BETWEEN timestamp '<yyyy-mm-dd hh:mm:ss>' AND timestamp '<yyyy-mm-dd hh:mm:ss>'--AND eventname IN (GetObject, 'PutObject', 'DeleteObject')
--AND userName = 'adminXX'--AND sessionUserName = '<ROLE_NAME>'--AND principalId LIKE 'AROA<xxxxx>:%'--AND arn LIKE '%user/admin%'--AND eventSource = '<SERVICE>.amazonaws.com'--AND sourceIPAddress LIKE '<x.x.x.x>'--AND bucketName = '<BUCKET_NAME>'--ORDER BY eventTime DESC
LIMIT 50;
このテンプレートではクエリ条件がコメントアウトされているため、実施したい検索に応じて必要なものをアンコメントできます。
以下は、AthenaツールとともにAWS-IReveal-MCPを使用する例です。
プロンプト:
Has any S3 data event occurred on buckets with name containing 'customers'in eu-central-1in the last 24 hours?
for Athena queries use s3://pallas-athenas/ in us-east-1 as output bucket
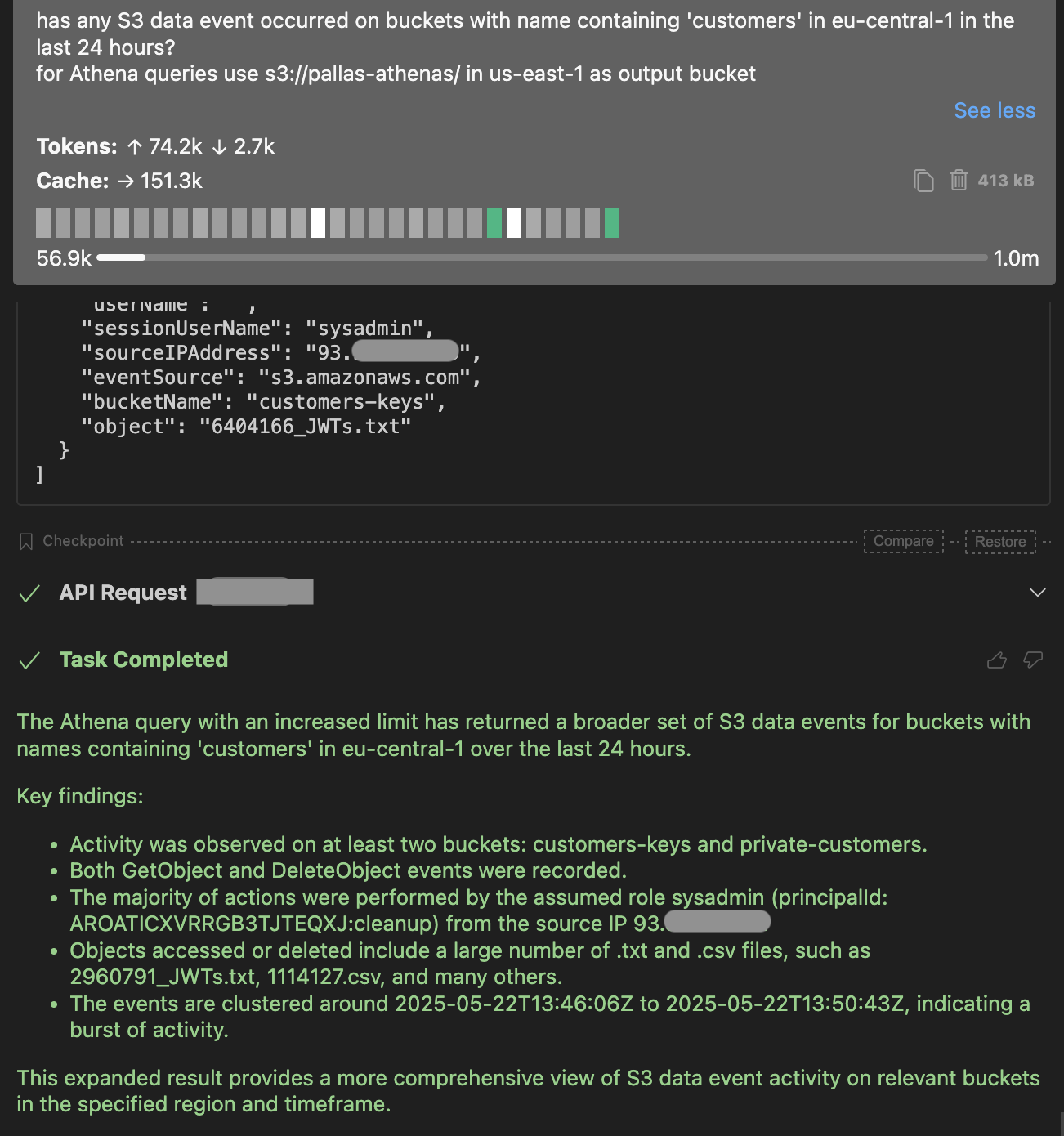
ここから、すでに重要な情報が得られています。
- 2つの重要バケットが影響を受けました:「customers-keys」と「private-customers」。
- 多数のファイルがダウンロードされ削除されており、ランサムウェア攻撃に典型的なパターンです。
- これらのAPIコールの発信元IPアドレスが分かるため、同じIPからの他のアクティビティも調査できます。AWS-IReveal-MCPに実装されたAthenaクエリテンプレートでそれが可能です。
- このアクティビティの実行主体はロール「sysadmin」で、攻撃者はセッション名「cleanup」でそれを引き受けています。ここから調査は次の問いに進むべきです。
- そのロールにAWSDenyAllポリシーをアタッチした後も、攻撃者はそのロールから永続化できたでしょうか。たとえば別ロールを引き受けたり、一時的認証情報を生成できたでしょうか。
- そのロールの権限は何でしょうか。攻撃者はその権限で他のサービスやIDを狙ったでしょうか。
- 誰がこのロールを引き受けられるのでしょうか(つまり、信頼ポリシーにおける信頼されたIDは何か)。
- このロールは何に使われているのでしょうか。EC2インスタンスプロファイルのロールでしょうか。この場合、攻撃者はIMDS経由で制御を奪った可能性があり、AssumeRoleは不要です。そうでない場合、攻撃者が呼び出したAssumeRoleのログを取得することが極めて重要です。攻撃中に生成されたAPIコールのログにあるPrincipal IDは、AssumeRoleログにあるresponseElements.responseElements.assumedRoleIdの値と一致しなければなりません。今回のケースでは「AROATICXVRRGB3TJTEQXJ:cleanup」です。
さまざまな攻撃シナリオをカバーする追加のAmazon Athenaクエリについては、オープンソースリポジトリaws-incident-responseを参照してください。
Amazon CloudWatch
多くのAWSサービスは、ログをAmazon CloudWatchへ送信するよう設定できます。サービス設定によっては、これらのログが非常に大量になる可能性があります。有効化することで、インシデント中に何が起きたのかを理解するうえで大きな違いが生まれます。
Simple Email Service(SES)
たとえば、脅威アクターがSES API(メール送信を含む)を呼び出す権限を持つユーザーまたはロールを侵害したとします。彼らはあなたのAWSアカウントから数千人のユーザーを標的にフィッシングキャンペーンを実行しました。SESがデータイベントをCloudWatchへ送信するよう設定されていれば、インシデント対応者は送信されたメールに関する有用な情報を多く取得できます。次のスクリーンショットは、SESを悪用してフィッシングメールを送信した実際の攻撃のCloudWatchログを示しています。

ご覧のとおり、このログには送信者のIPアドレス、送信者と受信者のメールアドレス、送信者のエイリアス、メール件名など、非常に関連性の高いデータが含まれています。
私たちは、次のように要約できる脅威検知と対応オーケストレーションを提案します。
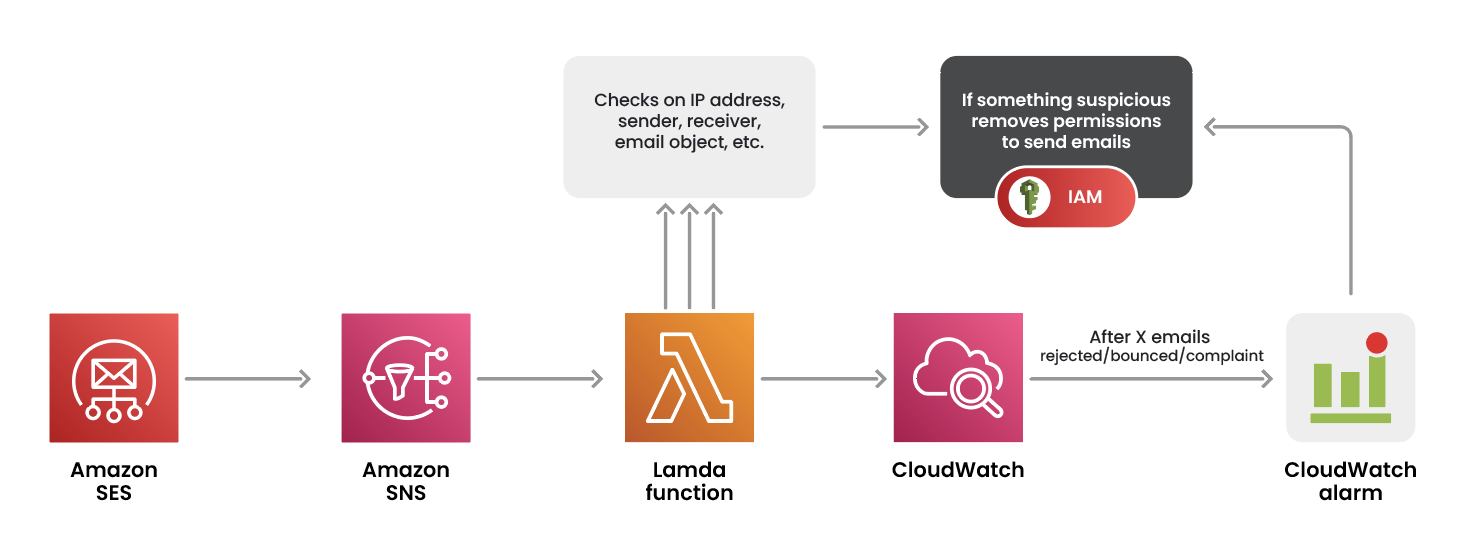
すべてはSESからのメール送信イベントから始まり、Amazon Simple Notification Service(Amazon SNS)トピックに発行され、それがLambda関数をトリガーします。この関数は、先ほどイベントログで示したフィールドに対してカスタムチェックを実行します。たとえばIPアドレスや送信者メールアドレスのホワイトリストを実装できます。1つ以上のチェックに失敗した場合、送信されたメールに何か不審な点があるかもしれません。その場合、Lambda関数は呼び出し元IDの権限を剥奪するなど、迅速に対応できます。これらのセキュリティチェックは単一のメールログに対して行われますが、複数メールにまたがる不審なパターンはどうでしょうか。CloudWatchは、拒否(rejected)、バウンス(bounced)、苦情(complaint)メールなどのメトリクスを提供することで助けになります。これらのメトリクスに対して閾値ベースのCloudWatchアラームを設定できます。
2025年4月、AWSはメール送信イベントのCloudTrailログ記録のサポートを導入しました。CloudTrailに依存して脅威検知を行う場合、これは間違いなく有用です。
Amazon Bedrock
調査中にCloudWatchログの恩恵を受ける別のサービス例として、Amazon Bedrockがあります。Bedrockは複数の大規模言語モデルを提供し、InvokeModelやConverseなどのさまざまなAPIで呼び出せます。Bedrockは呼び出しイベントのログをCloudWatchに記録します。これらの拡張ログには、ユーザープロンプト、モデル応答、対応するCloudTrailログには含まれない追加データが詳細に含まれます。
これらのデータは、LLMjacking攻撃のようなインシデントを調査する際に非常に役立ちます。
AWS-IReveal-MCPを活用して分析を支援できます。たとえば「CloudWatchにBedrock関連のロググループはありますか?」のように尋ねられます。
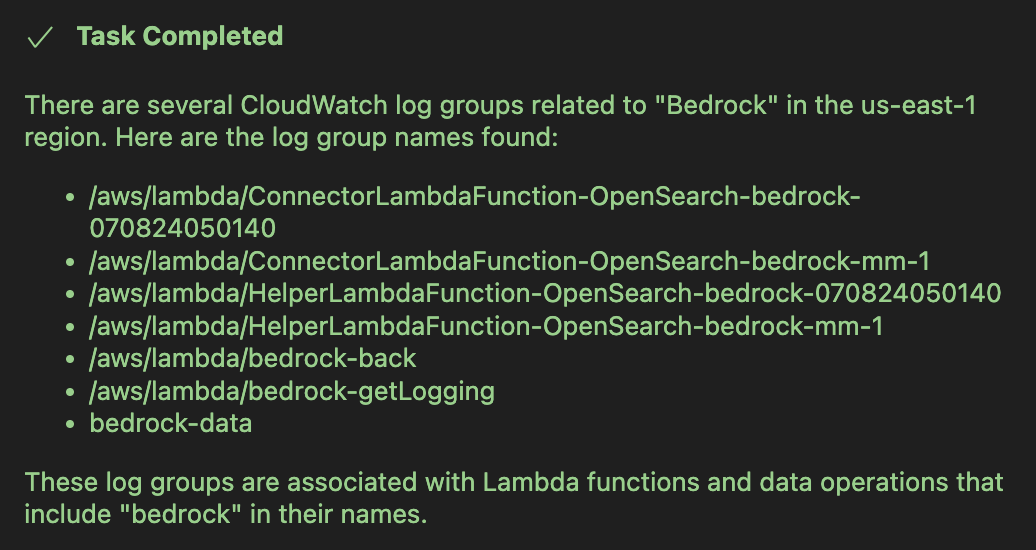
その後、「2025年2月のbedrock-dataロググループを調査しましょう」というプロンプトで、関連ロググループの調査を進められます。

Bedrockの将来的な悪用を防ぐために、組織内の権限を管理できるService Control Policies(SCP)を利用できます。これらのポリシーは、ルートアカウントを除き、組織内のすべてのアカウントにまたがるすべてのIAMユーザーとロールに適用されます。
たとえば、次のポリシーはすべてのAnthropicモデルの呼び出しAPIを拒否します。
{
"Version": "2012-10-17",
"Statement": {
"Sid": "DenyInferenceForAnthropicModels",
"Effect": "Deny",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:Converse",
"bedrock:ConverseWithResponseStream" ],
"Resource": [
"arn:aws:bedrock:*::foundation-model/anthropic.*" ]
}
}
組織内でBedrockをまったく使用していない場合、すべてのリソースに対してBedrockの全APIを拒否したいかもしれません。これはもちろん、あらゆるAWSサービスに対して有用な選択肢です。
侵害されたEC2インスタンスの調査
AWSアカウントへの初期アクセス獲得の一般的な方法は、EC2インスタンス上でホストされている脆弱または設定ミスのあるWebアプリケーションを悪用することです。AWSは、EC2インスタンスのフォレンジック分析を自動化するためにAutomated Incident Response and Forensics Framework、およびAutomated Forensics Orchestratorを提供しています。
これらには、分析をセットアップするために必要な次の重要ステップが含まれます。
- 侵害されたインスタンスがAuto Scalingグループの一部である場合、そのグループから外す。
- インスタンスにアタッチされたすべてのEBSボリュームのスナップショットを取得する。
- すべてのインスタンスメタデータ(パブリック/プライベートIPアドレス、AMI詳細、サブネットなど)を記録する。
- アタッチされているセキュリティグループをすべて外し、すべてのインバウンド/アウトバウンド接続を拒否する隔離用セキュリティグループに置き換える。
- すべてのAPIアクセスを禁止するIAMロールをアタッチする。
マシンを隔離した後、そのボリュームスナップショットはフォレンジックアカウントと共有する必要があります。その後、それらのスナップショットから新しいEBSボリュームを作成し、調査用にVPC内のプライベートサブネットで稼働するEC2インスタンスへアタッチします。
これでマシンの分析を進められます。マシンのOSに応じて、いくつかのオープンソースツールを使用できます。
- LiME(Linux Memory Extractor)。
- Volatility(メモリフォレンジックに使用)。
- The Sleuth Kit(ディスクイメージ解析のためのツールセット)。多くの機能の中でも、現在のマシンのファイルシステムと元のAMIのファイルシステムの「差分(diff)」を作成できます。これは、攻撃者がマシンに加えたごくわずかな変更であっても検出するのに非常に役立ちます。
- ssm-acquire(Mozillaが開発。SSM(Systems Manager)を使用してEC2インスタンスのメモリを取得・分析)。
- cloud-forensics-utils(Googleが開発。EC2インスタンスのフォレンジック分析をセットアップ)。仮想マシンの隔離、EBSスナップショット作成、外部フォレンジックインスタンスへのアタッチ、またはdc3dd(ディスクバックアップツールddのパッチ版)を利用するスクリプトでS3バケットへコピーする機能を実装しています。また、分析に使用するインスタンスにThe Sleuth Kitを含む複数のフォレンジックツールをインストールします。
多数のEC2インスタンスを運用している場合、脅威検知と対応の自動化は非常に有用です。GuardDutyの検出結果により、AWSが提供するフレームワークをトリガーして影響を受けたマシンを分析し、アカウント所有者へ通知し、分析レポートを送付できます。さらに詳細な分析のために追加ツールで拡張することも可能です。
調査したいEC2インスタンスを考えてみましょう。cloud-forensics-utilsをインストールした後、次のコマンドを実行して、インスタンスがあるアカウントから別のフォレンジックアカウントへボリュームをコピーします。
cloudforensics aws 'us-east-1c' copydisk --volume_id='vol-0f1af2a470d420440' --src_profile='hp2-adminB' --dst_profile='default'
次に、以下のコマンドで、指定したAMI、4CPU、50GBボリューム、そして侵害されたインスタンスからコピーしたボリュームを備えた新しいEC2インスタンスをフォレンジックアカウントで起動します。
cloudforensics aws 'us-east-1c' startvm 'vm-forensics' --boot_volume_size=50 --cpu_cores=4 --ami='ami-020cba7c55df1f615' --attach_volumes='vol-0db527dfcd85612f8' --dst_profile='default'
これで、新しいEC2インスタンスに接続して侵害されたボリュームを分析できます。
まずはThe Sleuth Kitの一部であるflsから始め、指定デバイス上のすべてのファイルとディレクトリエントリを列挙します。
sudo fls -r -m / /dev/xvdf1 > full.body出力ファイルをmactimeに入力し、時系列の「MACタイムライン」(Modify, Access, Change)をCSVファイルとして構築します。
sudo mactime -z UTC -d full.body > timeline.csvよりリッチなイベントベースのタイムラインとして、インスタンスに自動インストールされるフォレンジックツールに含まれるPlasoも活用できます。次のコマンドは、数百のアーティファクトソース(ファイルシステムのタイムスタンプ、Windowsイベントログ、macOSログ、ブラウザ履歴など)をスキャンし、イベントを/mnt/plaso.dumpに書き込みます。
sudo log2timeline.py /mnt/plaso.dump /dev/xvdf1最後に、次を実行してタイムラインをHTMLまたはCSVファイルとして作成できます。
sudo psort.py -o dynamic -w plaso_timeline.html /mnt/plaso.dumpこの手順により、ファイルシステムの変更を分析し、疑わしいボリューム上のアクティビティの完全なタイムラインを再構築できます。生のファイルシステムメタデータを「body file」に取り込み、SleuthKitのflsとmactimeでタイムスタンプ順に並べ替えることで、各ファイルの作成/変更/アクセス/変更(change)時刻を1つのCSVで確認できます。さらに、同じ生デバイスをPlaso(log2timelineとpsort)に取り込むことで、他の数百のアーティファクトソースを単一のタイムラインに重ね合わせられます。
次のスクリーンショットはpsortの出力の抜粋で、誰かがマシンのSSHログインをブルートフォースしようとしている証拠を示しています。
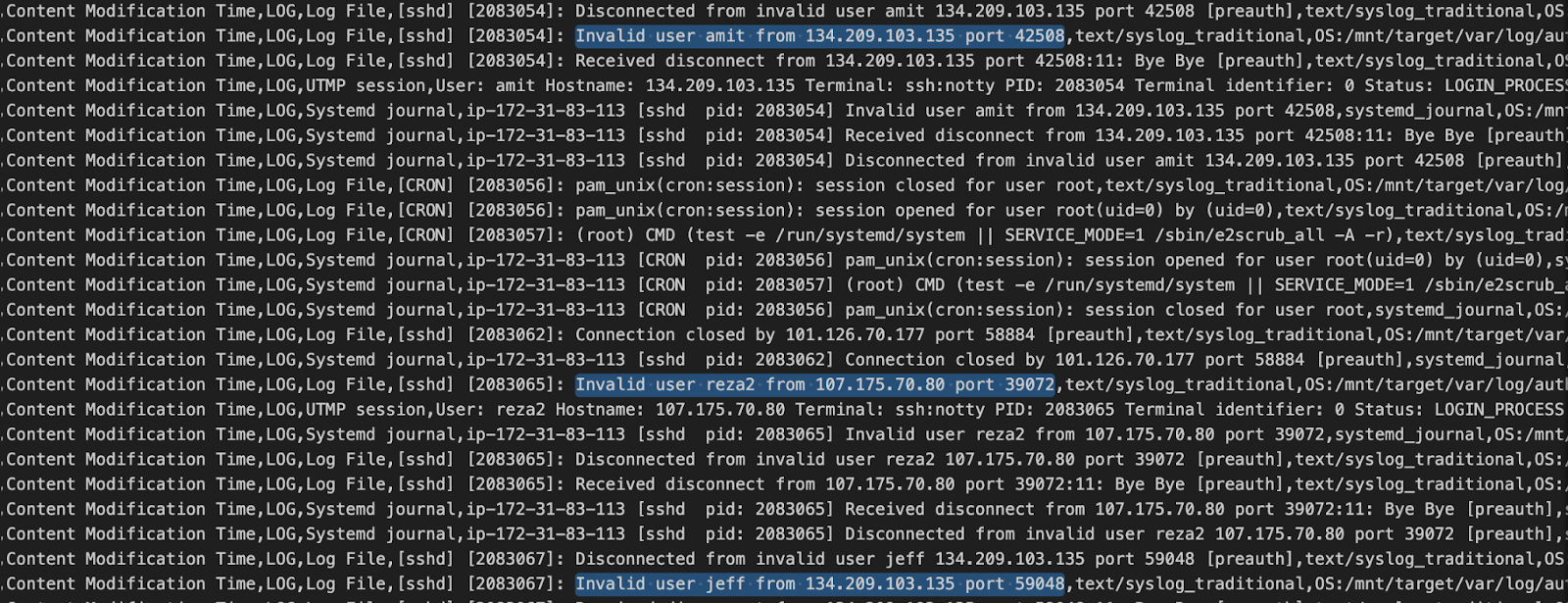
この情報がpsortによって取得されるのは、/mnt/target/var/log/auth.log.1ファイルがログイン試行のたびに更新されているためです。
関連するアイデアとして、現在のファイルシステムと元のAMIのファイルシステムを比較し、不審な変更を探すことも有用です。
悪意あるアクティビティのためのネットワークトラフィック分析
VPC Flow Logsは、VPC内のネットワークインターフェイスとの間で送受信されるネットワークトラフィックを捕捉し、悪意あるアクティビティ検知の重要なリソースとなります。これらのログはCloudWatch、S3バケット、またはAmazon Data Firehose(同一または別アカウント)へ配信するよう選択できます。CloudWatchでは、送信元/宛先ポート、送信元/宛先アドレス、プロトコルなど、さまざまなメトリクスフィルターに基づいてアラームを設定できます。1時間以内にEC2インスタンスへの拒否されたSSH接続試行が10回以上発生した場合のアラーム作成方法の例はこちらです。
その後、Amazon Athenaを使ってSQLクエリでネットワークトラフィックを分析できます。見慣れないIPアドレスへの接続、外部への大量データ転送、通常使用しないポートでのトラフィック、確立されたベースラインから大きく逸脱する通信パターンなど、異常なパターンを探してください。これらの所見をCloudTrailなど他のセキュリティログと相関させ、不審なネットワークアクティビティの発生源と文脈を特定します。拒否された接続は、脆弱性探索の試みを示す可能性があるため特に注意してください。Flow Logsを定期的にレビュー・分析し、通常のネットワーク挙動を強く理解することが重要です。組織のベースライン挙動を把握していれば、悪意を示す可能性のある逸脱を効果的に特定できます。
一般的な永続化手法の緩和
フェデレーション認証情報
IAMユーザーのキーが侵害されたことを検知した際の最初の対応は、多くの場合それらのキーを無効化または削除することです。しかし、キーが無効化される前に攻撃者がGetFederationTokenで一時的認証情報を作成できていた場合、これだけではそのユーザーの悪用を防げません。
このAPIは最大36時間(ユーザーがルートユーザーの場合は1時間)有効な一時的認証情報を作成します。呼び出し時にセッションポリシー(管理ポリシーまたはインライン)を渡せます。結果として得られるセッション権限は、IAMユーザーポリシーと提供されたセッションポリシーの共通部分(intersection)になります。
トークンの失効
「aws:TokenIssueTime」フィールドを用いたdeny-allポリシーを侵害されたユーザーにアタッチすることで、セッション権限を失効させるべきです。以下はここで報告されているポリシー例です。
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Deny",
"Action": "*",
"Resource": "*",
"Condition": {
"DateLessThan": {"aws:TokenIssueTime": "2014-05-07T23:47:00Z"}
}
}
}
フェデレーション認証情報の作成後の日付を設定することで、このポリシーはすべての権限を拒否します。さらに、環境でフェデレーテッドユーザーを利用していない場合は、GetFederationTokenの呼び出しを監視し、適切な検知ルールを実装することを検討してください。
バックドアロール
攻撃者がAWSアカウントへのアクセスを維持する一般的な方法は、IAMロールにバックドアを仕込むことです。これは、ロールの信頼ポリシーを変更し、攻撃者のAWSアカウントに属するIDがそのロールを引き受けられるよう指定することで実現されます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<ATTACKER_ACCOUNT_ID>:user/evil_user
]
},
"Action": "sts:AssumeRole"
}
]
}
ロールの信頼ポリシーを監視し、外部アカウントIDが引き受け可能なロールを検知してアラートするセキュリティ機構を用意すべきです。
別の永続的脅威として、互いに引き受け可能なロールの集合が挙げられます。攻撃者がそのうちの1つを侵害すると、別ロールを引き受けて認証情報を更新し、同様の操作を繰り返してアクセスを維持できます。ロールチェーンのドキュメントによれば、これらの認証情報の有効期間は最大1時間に設定できます。この手法はrole chain jugglingとして知られています。
EC2インスタンス
EC2インスタンスは、権限管理のためにインスタンスプロファイル(IAMロールのコンテナ)を使用します。これらの権限は、インスタンスがAWSサービスへアクセスするために必要です。インスタンスプロファイルのセッション認証情報を取得するには、インスタンスで設定されているIMDSv1またはIMDSv2が提供するエンドポイントを呼び出す必要があります。
EC2インスタンス上で動作するWebアプリケーションにRCEまたはSSRFの脆弱性を見つけた攻撃者は、それを悪用して認証情報を盗むことができます。これにより攻撃者はインスタンスプロファイルの権限を使用でき、被害者のAWSアカウントへのアクセスを維持できます。
IMDS経由で認証情報を盗む行為を迅速に検知するには、マシン上での適切なランタイム検知が必要です。この操作はAssumeRoleイベントを生成しないため、そのAPIの不審な呼び出し監視に頼ることはできません。代わりに、前述のとおりCloudTrailログのec2RoleDeliveryフィールドに頼れます。このフィールドは、API呼び出しに使用された認証情報がIMDSv1またはIMDSv2で生成されたかを示します。
EC2インスタンスロールからの不審イベントを検知した後の最初の対応は、やはりそのロールにdenyポリシーをアタッチし、過去のセッションを失効させることです。その後、DisassociateIamInstanceProfileを呼び出して、侵害されたインスタンスプロファイルをインスタンスから関連付け解除することを検討してください。攻撃の根本原因(Webアプリの脆弱性または設定ミス)を是正した後、そのEC2インスタンスに関連付けるための新しいインスタンスプロファイル(新しいキーセット)を作成すべきです。
ユーザーデータ
攻撃者がEC2インスタンスで永続化を維持する別の方法は、ユーザーデータを利用することです。ユーザーデータには、マシン起動時にrootとして実行されるコマンドが含まれます。攻撃者がModifyInstanceAttribute権限を持つIDを侵害していた場合、EC2インスタンスのユーザーデータを改変して悪意あるコードを挿入できます。ユーザーデータの変更にはインスタンスを停止する必要がある点に注意してください。そのため、StopInstances -> ModifyInstanceAttribute -> StartInstancesという一連のイベントは不審である可能性があるため監視すべきです。
リソースベースの手法
前述の永続化手法は運用上のものとみなせます。攻撃者がIAMロールや実行中のインスタンスにバックドアを仕込み、サービスやリソースの集合に対する制御を維持するケースです。別の種類の永続化は、RDSデータベースなどのリソースに紐づきます。
S3バケット、Lambda関数、SQSキューなどです。これらのリソースにバックドアを仕込むことで、攻撃者は被害者のAWSアカウント内のいかなるIDにもアクセスできなくても、それらを通過するデータへのアクセスを維持できます。緩和策と対応戦略は、影響を受けたリソースに応じて異なる場合があります。
- Amazon RDS: 手動スナップショットを取得し、パラメータグループ設定をエクスポートする。
- Amazon S3: ポリシーJSONとオブジェクトACLをコピーする。
- AWS Lambda: デプロイ済みコードパッケージをダウンロードする。
- Amazon SQS: キュー属性とポリシーをエクスポートする。
その後、次を実施してください。
- リソースのスナップショットまたは状態を、最後に既知の良好なInfrastructure as Code(IaC)定義と比較し、不正な変更を特定する。
- パブリックエンドポイントを切り離す、またはネットワークを制限する(例:RDSのセキュリティグループを厳格化する)。
- リソースポリシーから外部プリンシパルを直ちに削除する。
結論
インシデント対応は静的なプロセスではありません。変化し続ける脅威環境に対して有効性を保つため、絶えず洗練が求められる動的で進化する分野です。各インシデントから得られる教訓は、現在のインシデント対応計画に統合すべき貴重な洞察を提供します。この継続的なフィードバックループにより、組織の防御は常に適応し改善されます。継続的改善を促進するうえで、次の領域は特に重要です。
- 可能な限りインシデント対応アクションを自動化する:インシデント対応ワークフロー内の反復タスクやプロセスを特定し自動化することで、効率と一貫性を大幅に高められます。適切な脅威検知手段を実装し、ほぼリアルタイムのアラートを上げるべきです。これは自動対応アクションと組み合わせられます。たとえばEC2インスタンスに対するアラートが、インスタンスを隔離しフォレンジック分析用のスナップショットを作成する自動化をトリガーできます。
- 定期的なセキュリティ監査とペネトレーションテスト:攻撃者に悪用される前に脆弱性や弱点を特定するため、予防的なセキュリティ評価は不可欠です。内部・外部の定期監査により、設定、ポリシー、手順を業界ベストプラクティスやコンプライアンス要件に照らしてレビューできます。一方ペネトレーションテストは、現実世界の攻撃を模擬して、システム、アプリケーション、ネットワーク設定における悪用可能な脆弱性を特定します。現実世界の攻撃をシミュレートする非常に効果的なツールの1つがStratus Red Teamです。検知のテストは、潜在的な問題を特定して解決するうえで重要です。
- インシデント対応チームの訓練と意識向上:最先端のツールや技術も、それを使う人の能力次第です。インシデント対応チームが幅広いセキュリティインシデントに対処できるようにするため、継続的な訓練と意識向上プログラムが極めて重要です。組織全体で強いセキュリティ文化を育むことは、より強靭な全体セキュリティ態勢に寄与します。
継続的改善にコミットし、利用可能なリソースを活用することで、組織はAWSにおける非常に効果的なインシデント対応能力を構築でき、セキュリティインシデントの影響を最小化し、クラウド上の重要資産を保護できます。
翻訳元: https://www.sysdig.com/blog/build-your-aws-incident-response-playbook-with-open-source-tools


